library(igraph); library(qgraph)
g1 <- graph(edges = c(1,2, 2,3, 3,1),
n = 3, directed = FALSE)
plot(g1) # an undirected network with 3 nodes
g2 <- graph(edges=c(1,2, 2,3, 3,1, 1,3, 3,3),
n = 3, directed=TRUE)
plot(g2) # an directed network with self-excitation on node 3
get.adjacency(g2) # weight matrix
fcn <- make_full_graph(10) # a fully connected network
plot(fcn, vertex.size = 10, vertex.label = NA)
layout(1)
set.seed(1)
adj <- matrix(rnorm(100, 0, .2), 10, 10) # a weighted adjacency matrix
adj <- adj * sample(0:1, 100, replace = TRUE,
prob = c(.8, .2)) # set 80% to 0
qgraph(adj) # plot in qgraph
edge_density(fcn) # indeed 1
edge_density(graph_from_adjacency_matrix(adj, weighted=TRUE))# now .2
centralityPlot(qgraph(adj)) # note centrality() gives more indices6 Psychological Network Models
6.1 Introduction
Common-cause theories are widely accepted in psychology. High scores on cognitive tests are attributed to high intelligence. Charisma is associated with various leadership qualities. A high score on the \(p\) factor (psychopathology factor) is associated with various mental health problems. The common-cause explanation is popular because of its simplicity and the availability of statistical methods such as factor analysis. In most cases, however, the common cause is only a hypothetical construct. Yet many people accept common-cause theories because they see no alternative. This is incorrect. Complex-systems theory offers a powerful alternative, including a statistical approach. The main thesis of this chapter is that the functioning (and dysfunctioning) of the human mind is often best understood as a complex interplay of various psychological elements such as cognitive functions, mental states, symptoms, and behaviors.
Common-causes are questionable if they cannot be identified independently of the observed relationships they are intended to explain.The interplay of psychological subsystems can be modeled in terms of networks: psychological networks.
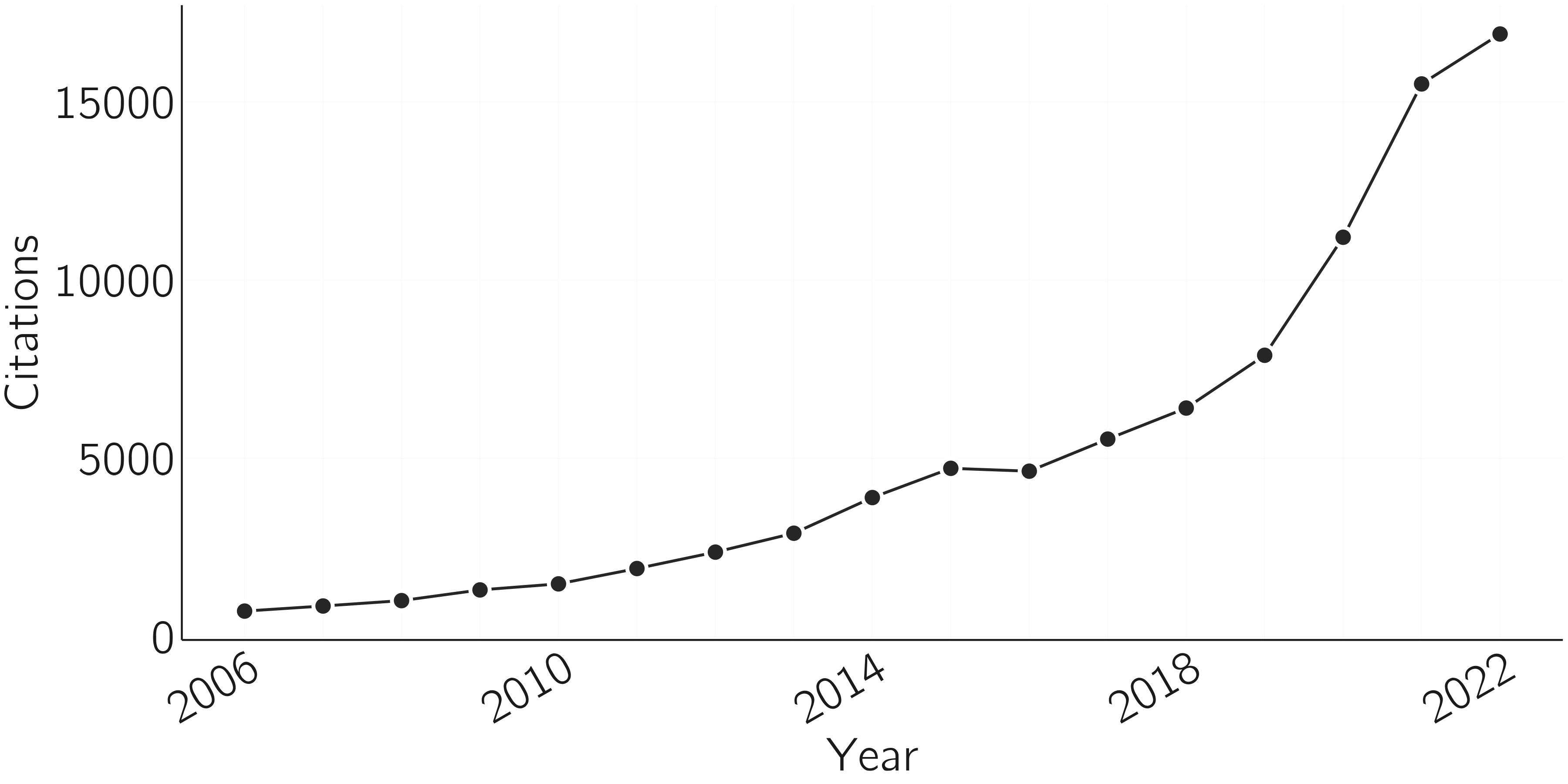
The study of psychological networks is probably the most thriving area of complex-systems research in psychology today. This chapter is about this new line of research. The paper on the mutualism model of general intelligence (van der Maas et al. 2006) can be seen as the root of this approach, but it took off, as shown in figure 6.1, when it was applied to clinical psychology (Borsboom 2017, 2008; Cramer et al. 2010), especially when the theoretical work was backed up with psychometric tools (Epskamp, Borsboom, and Fried 2018; Epskamp et al. 2012; Marsman and Rhemtulla 2022).
In this chapter I will present and discuss these theoretical and psychometric lines of research, accompanied by practical examples. First, I will begin with an introduction to network theory.
6.2 Network theory
It is hard to imagine a discipline in which networks are not a central theme. Networks are the key to understanding systems ranging from particle physics to social networks, from ecosystems to the internet, and from railways to the brain. The mathematics of network theory is not so easy to grasp, but fortunately the basic concepts are.
6.2.1 Network concepts
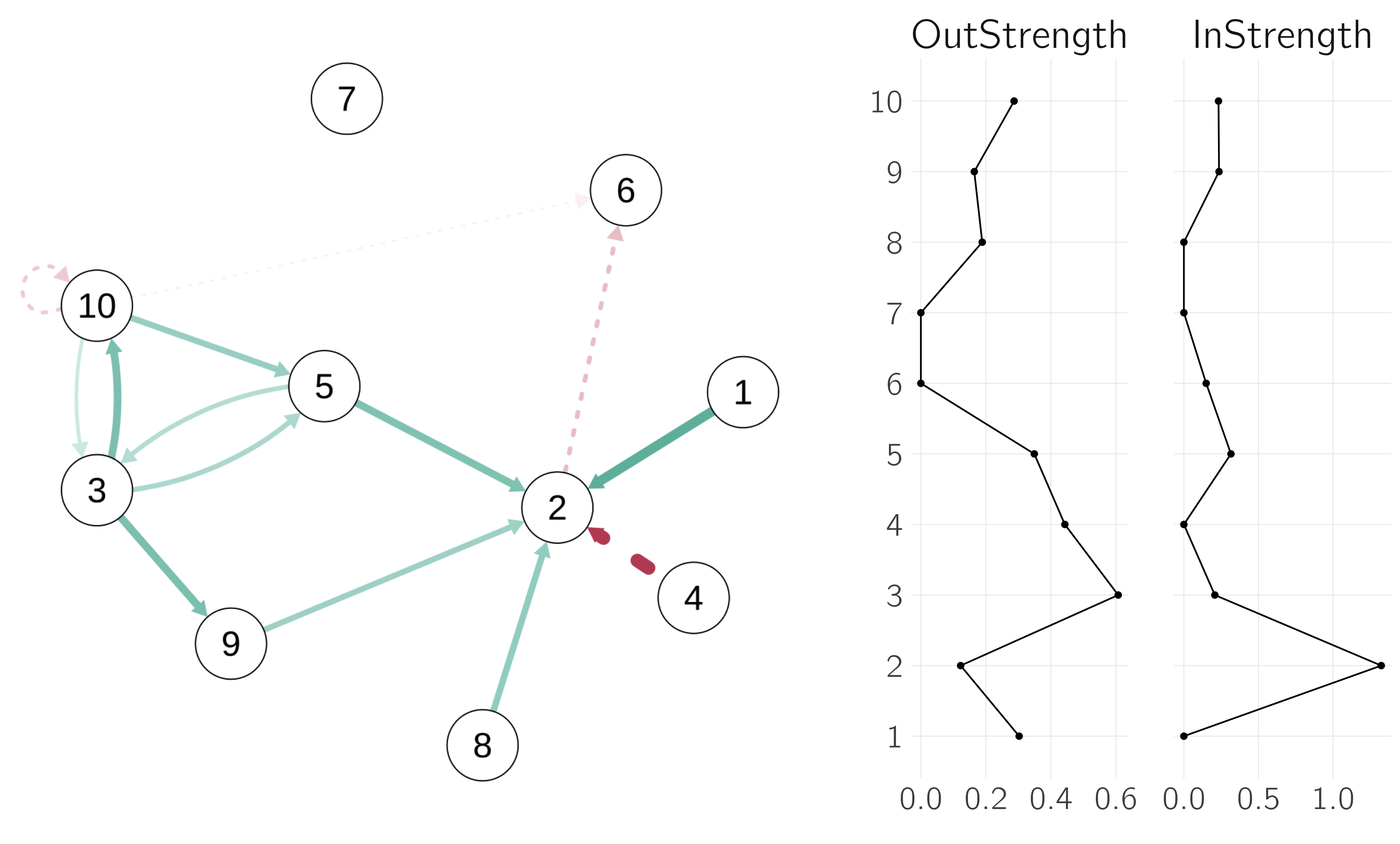
Nodes can be anything—particles, neurons, words, people, train stations, etc. The size of a network is equal to the number of nodes. Nodes are connected by links. Links can be directed or undirected. For example, causal links are directed. Occasionally you see links from the node to itself. In causal networks, this may represent self-excitation, or if the weight is negative, self-inhibition. In some cases, links are simply present or absent; in other cases, links are weighted, as in most neural networks. The matrix of all weights, indicating the strengths of the connections between nodes, is called the adjacency or edge matrix. For an undirected network, the adjacency matrix is symmetric. For a network without self-loops, the diagonal of the adjacency matrix is 0.
A network, a special type of graph, consists of nodes (often called vertices) and links (or connections or edges).
A connected network is a network in which every node is connected to every other node, possibly through intermediate nodes. In a fully connected network, or complete graph, every node is directly connected to every other node. Such a network has a density of 1 (i.e., the proportion of edges that is present).
Nodes can be in the center of a network or in the periphery. This should not be taken literally as psychological networks have no spatial dimension. There are many kinds of centrality measures, such as closeness centrality and degree centrality. The degree of a node is equivalent to the number of links it has. The average degree of a network is the average of the number of links over all nodes.
Centrality measures quantify the relative influence, control, or connectivity of a node compared to other nodes in the network.
The degree distribution can take several forms. A random graph, where nodes are connected randomly, has a binomial degree distribution. Most real-world networks have a skewed degree distribution. The average shortest path length (ASPL) is the average number of edges that must be traversed to get from one node to another using the shortest paths (i.e., the fewest intermediate nodes).
There are many methods available in R for creating and visualizing networks and for computing properties of networks. The igraph and qgraph libraries are very useful. It is a good idea to experiment with this R code below by varying the parameter values. Some key concepts of networks are shown in figure 6.2.
6.2.2 Network types
Simple networks do not have cycles. An example of an undirected acyclic graph is one with nodes on a line (but not a circle). Connected undirected acyclic graphs are trees; if they are partially unconnected, they are forests. Directed acyclic graphs, such as family trees and citation networks, are called DAGs. Most current neural networks are feedforward networks without cycles, but so-called recurrent networks have cycles.
Igraph1 has an amazing number of functions for creating specific networks. Some examples are shown in figure 6.3.
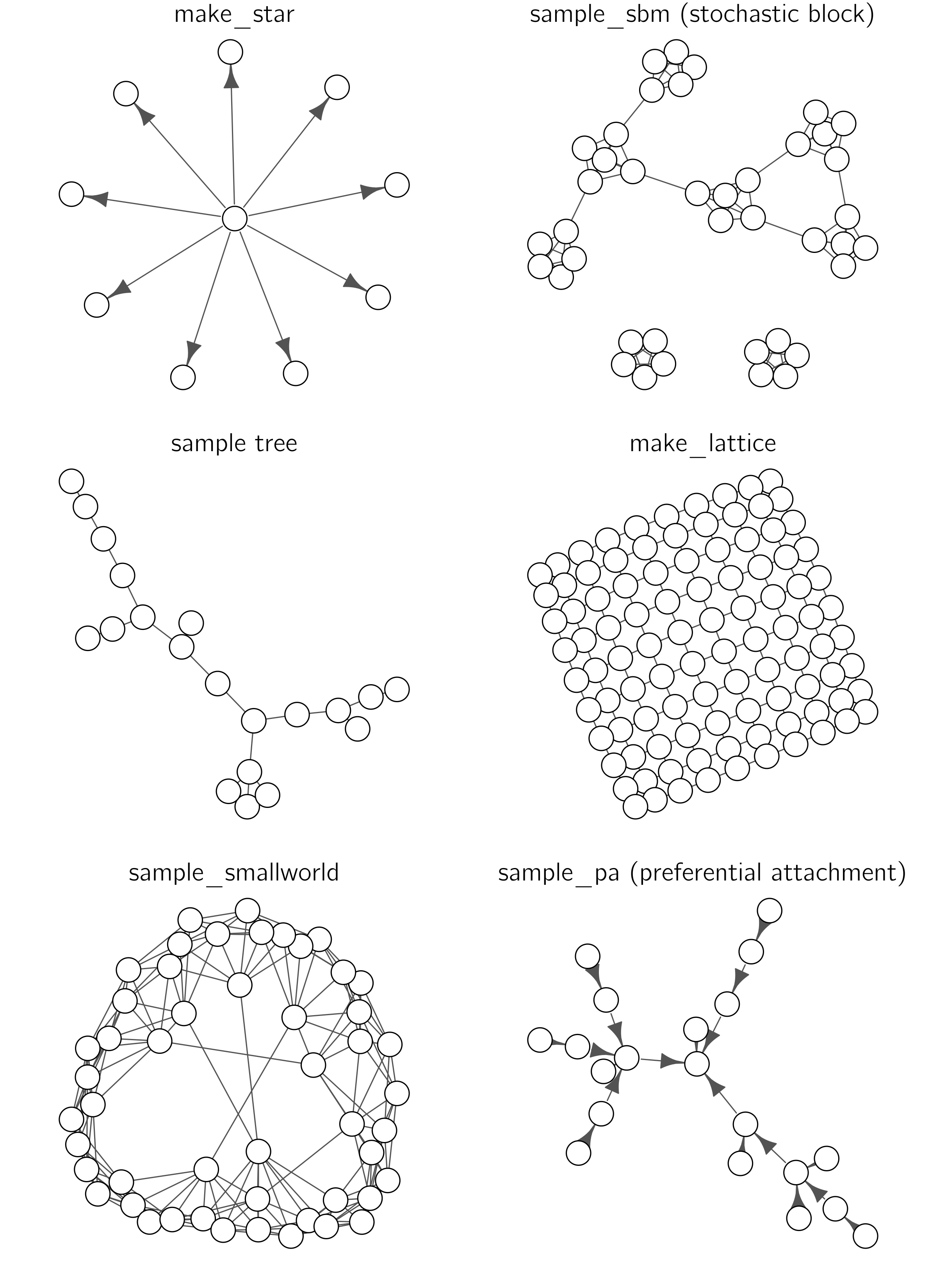
The last case in the figure, preferential attachment, is of particular interest because it is created dynamically. It starts with a node and then new nodes are added that prefer links to nodes that already have many links. In the NetLogo model “Preferential Attachment simple,” you can see this growth process. Preferential attachment networks are often called complex because they exhibit nontrivial structural patterns. Preferential attachment networks are “scale-free,” meaning that the degree distribution looks the same no matter the scale. Scale-free networks are useful for studying the robustness and vulnerability of networks to targeted attacks on highly connected nodes. Removing hubs with high connectivity potentially split the network into disconnected components and impede the network’s functionality. Because most nodes in the network have a small degree (few connections), randomly removing nodes tends not to disrupt the network’s overall structure. Scale-free networks are believed to exist in various real-world scenarios, ranging from website connections to scientific collaborations. For a critical analysis, I refer to Broido and Clauset (2019).
Scale-free networks have a degree distribution that follows a power law, with some nodes having many links but most having only a few.
Another type of complex network is the small-world network. The distance between any two nodes in such a network is always relatively short. A famous example is the six-handshake rule (also known as the six degrees of separation), which states that all people are six or fewer handshakes away from each other.2 For this reason, small-world networks are useful for studying the spread of information or disease through social networks.
Small-world networks consist of clusters, but there are also links between the clusters.
The scale-free and small-world networks are predominantly associated with the complex-systems approach. However, I believe that the hierarchical or nested stochastic block model (HSBM) is equally relevant (Clauset, Moore, and Newman 2008). The HSBM extends the SBM concept: clusters are nested within larger clusters, which in turn are part of even larger clusters in a continuous sequence (see figure 6.4), resembling fractals.
In the stochastic block model (SBM), nodes are organized into clusters with connections being stronger or more frequent within these clusters than between them.
This nesting seems to be crucial for understanding complex systems and is a central theme in Herbert Simon’s influential architecture of complexity (Simon 1962). He introduced the concept of near decomposability to describe the interaction within these nested hierarchies. Typically, interactions within each subsystem are stronger and more frequent than those between subsystems. Although the HSBM simplifies reality, where levels can intermingle and low-level interference might occasionally escalate to higher levels, it often serves as a useful framework for conceptualizing complex networks, including in the field of psychology.

6.2.3 Network dynamics
A prominent phase transition in network theory is the emergence of a giant component. This happens when we start with a completely unconnected network of \(n\) nodes and randomly add links. We simply take a random node and connect it to another node to which it has no connection. This leads to many small unconnected clusters at first, but then a giant component appears (a second-order phase transition). This happens when about \(n/2\) links have been added. You can verify this in the NetLogo model “Giant Component.” The implication is that randomly connected networks with a sufficient number of links are almost always connected networks.
In a random graph or network, as the density of edges increases beyond a certain threshold, a phase transition occurs where a giant component suddenly appears.
This is just one example of network dynamics (Dorogovtsev and Mendes 2002). We can distinguish between dynamics on node values (e.g., Lotka—Volterra models), on link values (connection strength in neural networks), and cases where the structure of the network is dynamic, as in the giant component example. These types of dynamics also coexist and interact. In neural networks, both node and link values are updated (on fast and slow time scales). We will see more examples in the next chapter.
A relatively new topic in complex networks concerns higher-order interactions. In most networks, we only consider pairwise interactions, but third-order and even higher-order interactions may play a role (Battiston et al. 2021). Other work considers hierarchical complex networks (Boccaletti et al. 2014). For more information on network concept and types, I first refer to Wikipedia. Another great (open) source is the book by Barabási and Pósfai (2016). A more concise overview is provided by Boccaletti et al. (2014).
6.3 Psychological network models
Differential psychology is concerned with individual differences, in contrast to experimental psychology, which is concerned with mechanisms. This division comes from a renowned paper by Cronbach (1957) on the two disciplines of scientific psychology. Cronbach distinguished between the how question (how does one read a sentence) and the why question (why do we differ in reading). The latter is typical of differential psychology. The latent variable or factor approach has long been dominant in differential psychology. When studying individual differences in a trait, psychologists generally follow the same approach. They construct tests, collect data, perform factor analysis, and propose one or more latent traits to explain observed individual differences. The justification for this approach, particularly in intelligence research, rests primarily on its predictive power (van der Maas, Kan, and Borsboom 2014).
Latent variables are used in statistical modeling to represent unobservable or underlying factors that cannot be directly measured or observed.
The statistical tools for analyzing latent variables come from modern test theory and structural equation modeling (SEM). These technically advanced tools are developed in a field called psychometrics. However, despite this technical sophistication, it is often not clear what latent variables are in psychometric models. Some researchers tend to think of them as purely statistical constructs that help summarize relationships between variables and make predictions. But more often, either implicitly or explicitly, latent variables are interpreted as real constructs, as common causes of observed measures (van Bork et al. 2017). The psychological network approach was developed in response to the factor approach. The main motivation for the network approach is that underlying common causes are unsatisfactory if they cannot be identified independently of the observed relationships they are supposed to explain (van der Maas et al. 2006). One consequence is that such an explanation does not provide guidance for possible interventions.
6.3.1 Mutualism model: The case of general intelligence
6.3.1.1 The \(g\) factor
The factor-analysis tradition in psychology began with the study of general intelligence, and so does the psychological network approach. The factor or \(g\) model of general intelligence was proposed by Spearman (1904) as an explanation of the positive manifold, that is, the much-replicated effect that subtests of intelligence test batteries are positively correlated. In the original simplest model, the observed test scores are statistically explained by a common factor, basically meaning that the correlations between test scores disappear when subjects have the same score on the common factor. In the Cattell-Horn-Carroll (CHC) model, often referred to as the standard model, test scores load on subfactors such as visual processing (Gv) and fluid reasoning (Gf), which in turn are positively correlated. These latent correlations are explained by the general, higher-order factor \(g\) (figure 6.5).
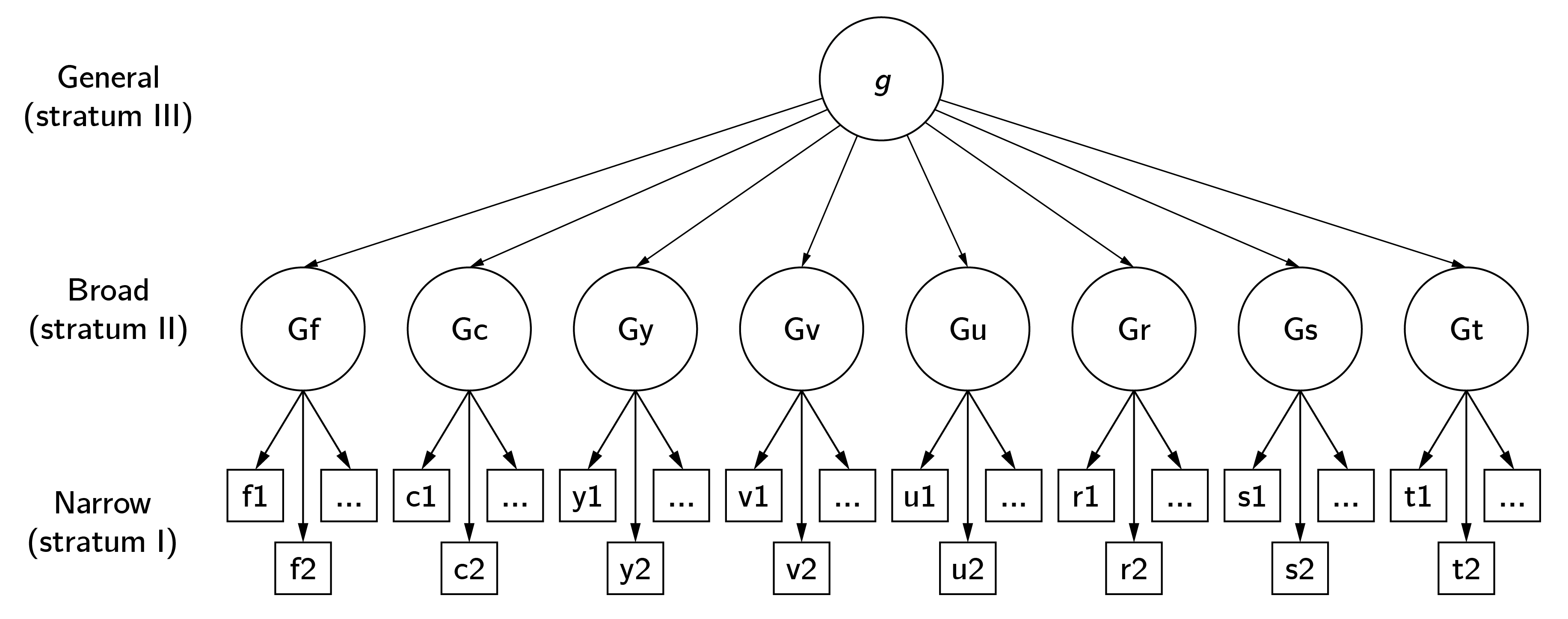
This model has been criticized extensively, including for its alleged implications for group differences in observed IQ and intervention strategies (Fraser 2008). In my view, some of the criticism is unwarranted. For example, the positive manifold is a very robust and widely replicated empirical phenomenon (Nisbett et al. 2012). The specific tests included are not of great importance. That is, any reliable measure of creativity, emotional intelligence, or social intelligence correlates positively with other IQ subtests. Nor is there much wrong with factor analysis as a statistical technique. To me, the most questionable aspect of \(g\) theory is that it is not really a theory at all. The “elephant in the room” question is simply: What is \(g\)? What could this single factor be that explains everything? A century of research has not produced a generally accepted answer to this question. And this is a problem for many factor explanations in psychology (e.g., the big five of personality, the \(p\) factor of psychopathology).
It is important to note that the factor explanations are not problematic in and of themselves. I like to use the example of heart disease, say, a loose heart valve. This leads to symptoms such as shortness of breath, swelling of the ankles, dizziness, rapid weight gain, and chest discomfort. The relationship between these symptoms is explained by the underlying factor of heart disease. Treating a single symptom may provide some relief for that symptom, but not more. Only intervening on the cause will bring about real change. This is an example of a reflective interpretation of the factor model. When the factor is merely an index and not a common cause, we speak of a formative factor. Figure 6.6 explains the reflective and formative interpretations of the factor model.
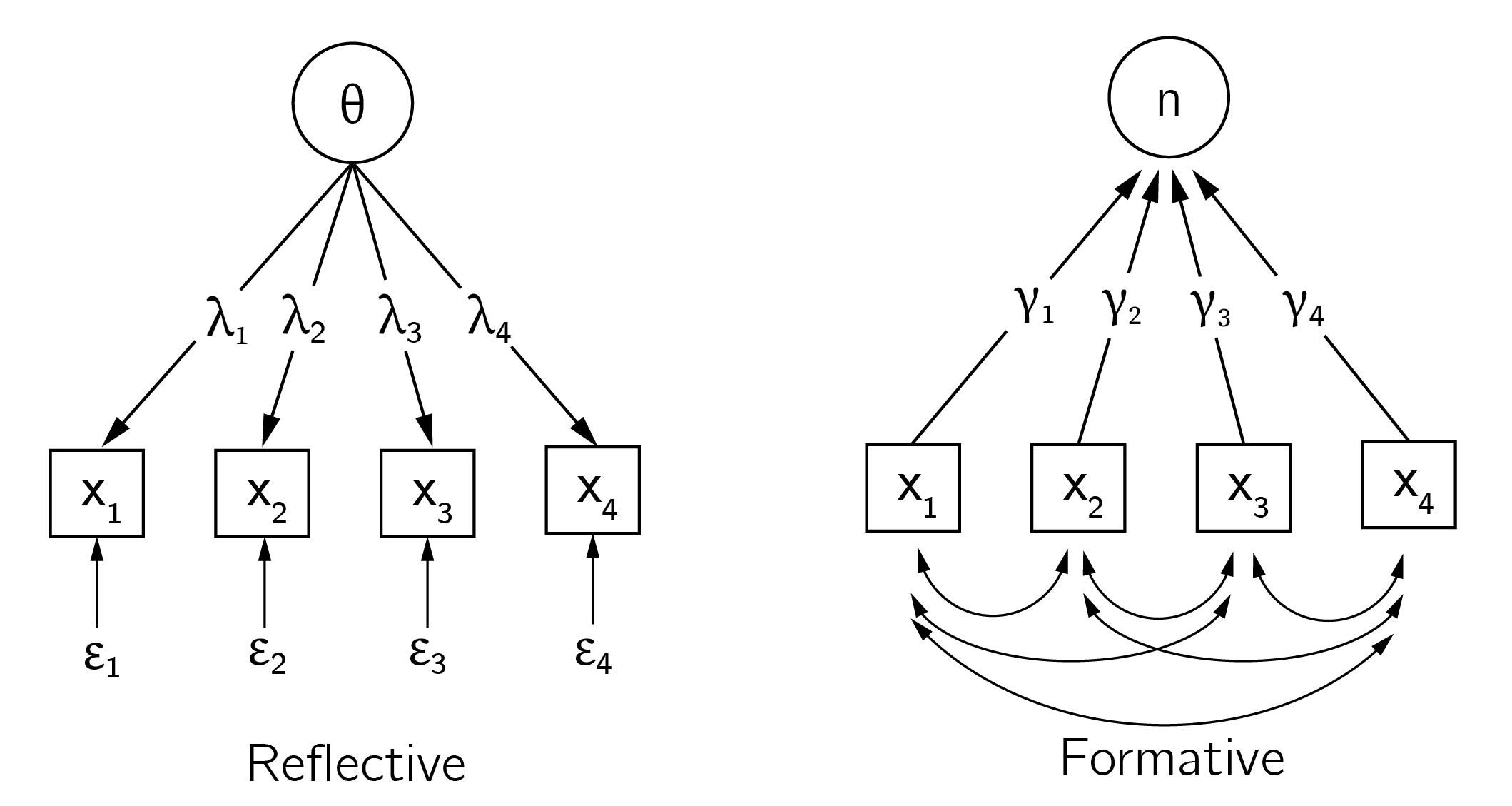
Statistically, these factor models are equivalent. Thus, the fact that factor models fit intelligence data well does not tell us anything about the status of statistical factor \(g\).
Is \(g\) a common cause or just an index?
6.3.1.2 Mutualism model
In van der Maas et al. (2006), we proposed an alternative model that is consistent with the formative interpretation of the factor model. The idea is that our cognitive system consists of many functions that develop over time in an autocatalytic process based on experience and training but also due to weak positive reciprocal interactions between developing cognitive functions (figure 6.7). Examples of such mutualistic interactions are those between short-term memory and cognitive strategies, language and cognition (syntactic and semantic bootstrapping), cognition and metacognition, action and perception, and performance and motivation (van der Maas et al. 2017). For example, babies learn to grasp objects by repeatedly reaching out, coordinating their hand and finger movements, and adjusting their grip. Through these actions, they gather sensory feedback, refining their perception and improving their grasping skills in a reciprocal learning process (Needham and Nelson 2023).
These mutualistic interactions can create correlations that are typically associated with factor models.
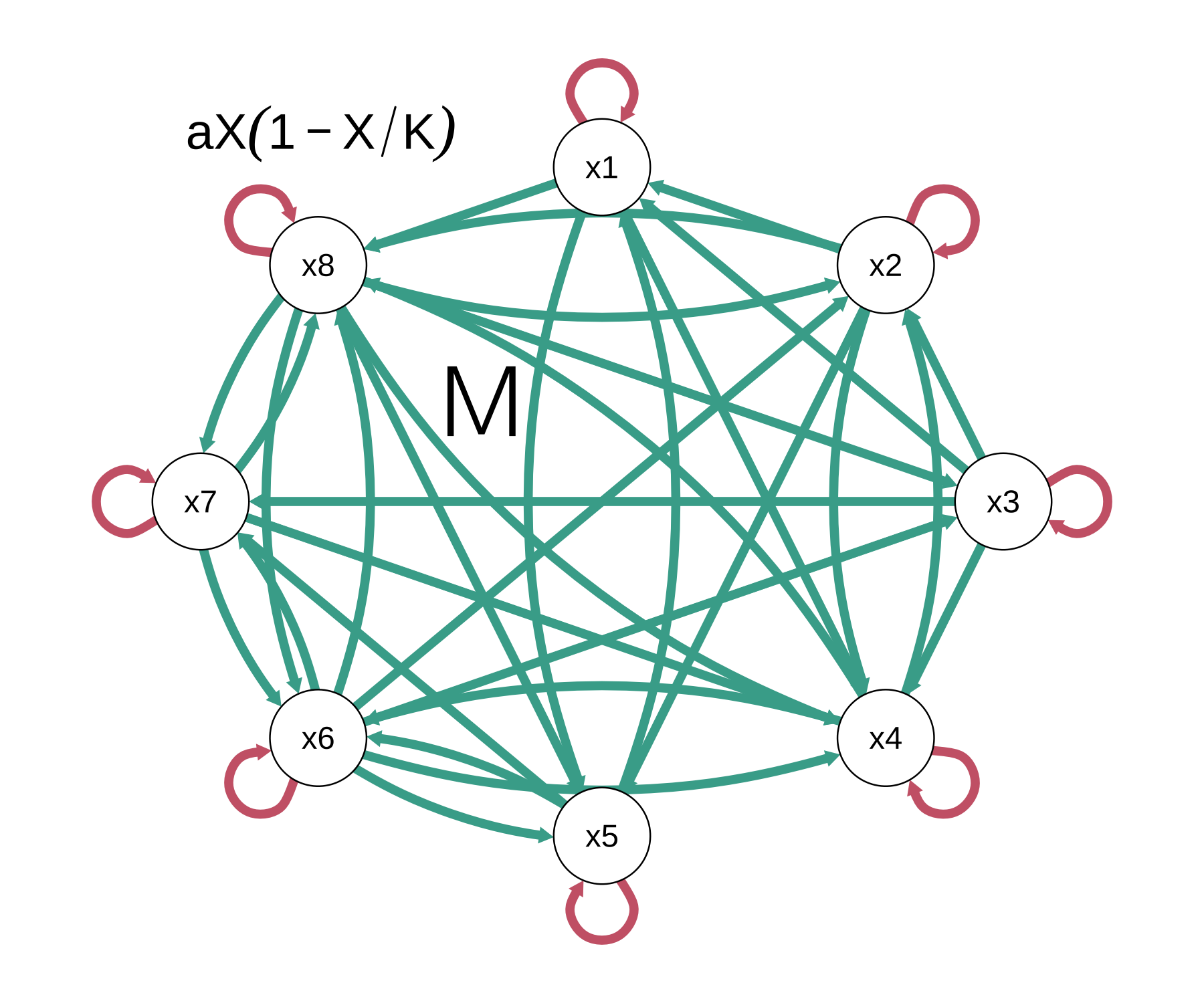
To model this, we used the mutualistic Lotka—Volterra model:
\[ \begin{gathered} \frac{dX_{i}}{dt} = a_{i}X_{i}\left( 1 - \frac{X_{i}}{K_{i}} \right) + a_{i}\sum_{\begin{array}{r} j = 1 \\ j \neq i \end{array}}^{W}\frac{M_{ij}X_{i}X_{j}}{K_{i}}\ \ \ for\ i = 1..W, \\ K_{i} = c_{i}G_{i} + \left( 1 - c_{i} \right)E_{i}, \end{gathered} \tag{6.1}\]
where \(X_{i} \ldots X_{w}\) denote the cognitive processes, \(\mathbf{a}\) the growth rates, \(\mathbf{K}\) the limited resources for each \(X_{i}\) (a weighted sum of a genetic (\(\mathbf{G}\)) and an environmental (\(\mathbf{E}\)) part), and \(\mathbf{M}\) the interaction matrix. The second equation, assuming simple linear effects of genetics and environment, is sufficient to explain some typical phenomena in twin research, such as the increase in heritability with age (see van der Maas et al. 2006). Criticisms and tests of the mutualism models, as well as alternatives, are discussed in van der Maas et al. (2017). Knyspel and Plomin (2024) compare the mutualism model with the factor model using twin data. Here we focus on the technical aspects.
When \(M\) contains mostly negative values, the model is known as a competitive Lotka—Volterra model. In this case, limit cycles and other nonlinear phenomena may occur (Hirsch 1985). For the mutualistic variant, with positive \(M\), we see either convergence to a positive state or exponential growth. This exponential growth is an unfortunate aspect of the Lotka—Volterra mutualism model. Robert May famously described this effect as an orgy of mutual benefaction (May, Oxford, and McLean 2007), which is not what we see in nature, and all sorts of solutions have been proposed (Bascompte and Jordano 2013).
The mutualism model in Grind is specified as follows:
mutualism <- function(t, state, parms){
with(as.list(c(state, parms)),{
X <- state[1:nr_var]
# using matrix multiplication:
dX <- a * X * (1 - X/k) + a * (X * M %*% X)/k
return(list(dX))
})
}A simulation of the positive manifold requires us to run this model for multiple people and collect the \(X\)-values after some time points (tmax = 60) for each person. We can then compute the correlations and check if they are positive (figure 6.8). For each person, we resample \(a\), \(K\), and the initial values of \(X\), but \(M\) is the same across persons. Note that the \(M\)-values should not be set too high, otherwise we end up in May’s orgy of mutual benefaction. In the second part of this chapter, we will generate more data with this model and fit network and factor models.
layout(matrix(1:2, 1, 2))
nr_var <- 12 # number of tests, abilities (W)
nr_of_pp <- 500
data <- matrix(0, nr_of_pp, nr_var) # to collect the data in the simulation
M <- matrix(.05, nr_var, nr_var)
M[diag(nr_var) == 1] <- 0 # set diagonal of M to 0
for(i in 1:nr_of_pp){
# sample a,K, starting values X from normal
# distributions for each person separately
# note M is constant over persons.
a <- rnorm(nr_var, .2, .05)
k <- rnorm(nr_var, 10, 2)
x0 <- rnorm(nr_var, 2, 0.1) # initial state of X
s <- x0; p <- c() # required for grind
# collect data (end points) and plot person 1 only:
data[i,] <- run(odes = mutualism , tmax = 60,
timeplot = (i==1), legend = FALSE)
}
hist(cor(data)[cor(data) < 1], main = 'positive manifold',
xlab = 'between test correlations',
col = 'grey50') # positive manifold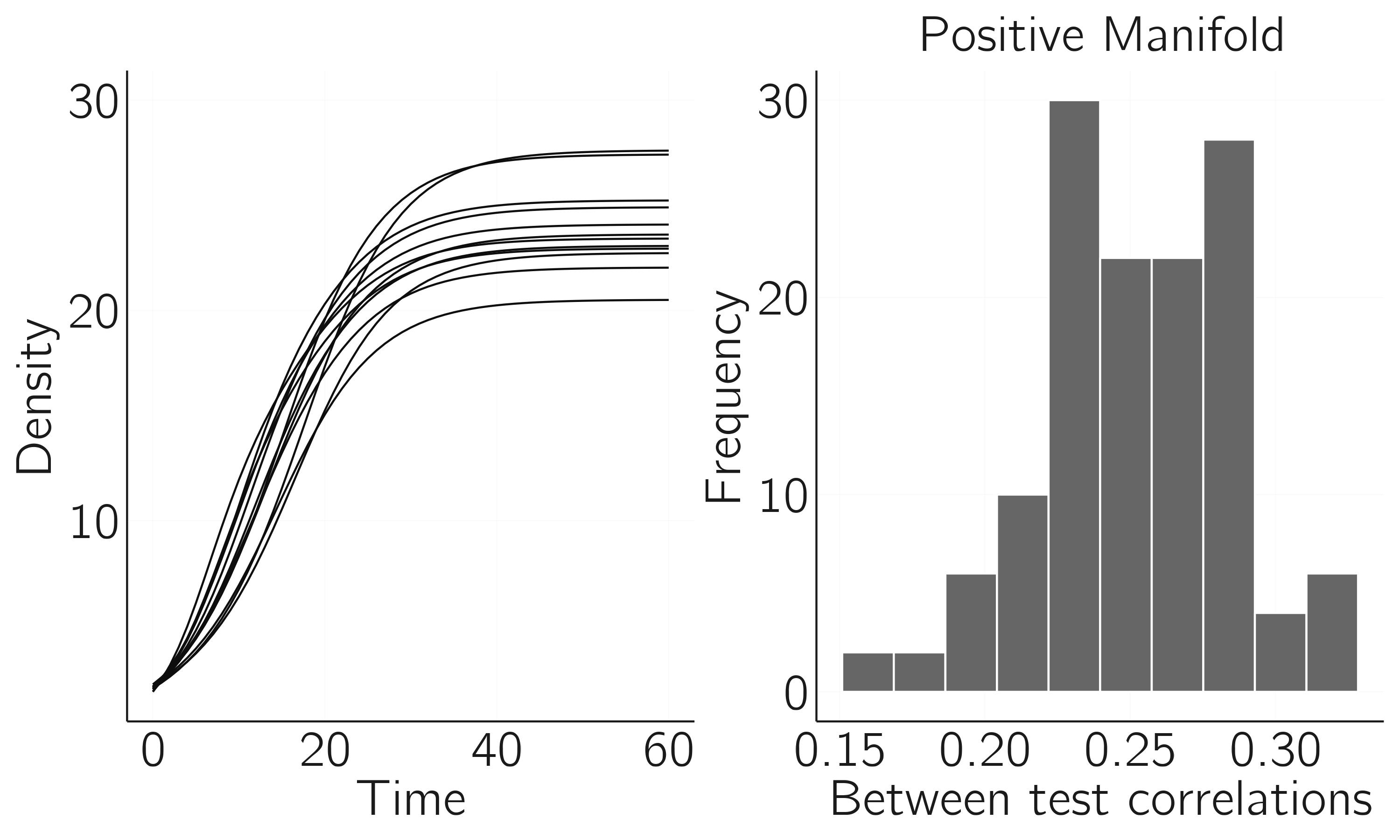
6.3.1.3 Abnormal development
In van der Maas et al. (2017), this model is applied in several ways, for example, by incorporating Cattell’s idea of investment of fluid skills in crystalized abilities (discussed in Section 4.5). In a recent paper, de Ron et al. (2023) extend the mutualism model with resource competition to explain different patterns of abnormal development. In the process of modeling, we came to an interesting insight. Assuming that there is competition for scarce resources (time, money, educational support), hyperspecialization might be the default outcome, and thus it is “normal” development that needs to be explained. The reason is an insight from mathematical biology: ecosystem diversity is often unstable. An example we have already seen is hypercycle instability due to parasites (Section 5.2.3). This is normally studied in resource competition models.
One pattern of abnormal development is hyperspecialization, which is associated with rare variants of autism.Ecosystem diversity is often unstable.
In basic resource competition models in population biology (Tilman, Kilham, and Kilham 1982), the growth of a species (\(1...W\)) is determined by its current size \(X_{i}\) and the sum over resources \(R_{j} (1...V)\). The parameters \(\mu_{ij}\) determine how much species \(i\) benefits from the resource \(j\). If no resources are available, \(X_{i}\) dies out with death rate \(d_{i}\).
The growth of the resource \(R_{j}\) consists of two parts. The first part models the growth by a concave function, which is determined by \(r\) (i.e., the steepness of the concave function) up to \(r_{\max}\). The second part is the depletion by consumption of resources by \(X_{i}\) at rates \(b_{ij}\). Two differential equations specify these dynamics (see the appendix of de Ron et al. 2023 for the Grind code to study this model numerically):
\[ \begin{gathered} \frac{dX_{i}}{dt} = X_{i}(\sum_{j = 1}^{V}{\mu_{ij}R_{j} - d_{i}}), \\ \frac{dR_{j}}{dt} = {r\left( r_{\max} - R_{j} \right) - R}_{j}\sum_{i = 1}^{W}{b_{ij}X_{i}}. \end{gathered} \tag{6.2}\]
What has been shown for this and related models is that you will not get more species surviving than there are resources. Another famous quote from Robert May is “There is no comfortable theorem assuring that increased diversity and complexity beget enhanced community stability; rather, as a mathematical generality, the opposite is true. The task, then, is to elucidate the devious strategies which make for stability in enduring natural systems. There will be no one simple answer to these questions” (p.174, 2001 edition). Thus, given a limited number of resources (time, money, educational support), we should expect early specialization in only a few skills.
Biologists have proposed a number of mechanisms to deal with this problem (Meena et al. 2023). In de Ron et al. (2023), we added three mechanisms: density-dependent growth (see Section 4.2.2) of the abilities \(X\) with a logistic term; mutualism between abilities as in the mutualism model; and growth-dependent depletion of resources. The idea of the latter is that the growth of abilities costs a lot of resources, but the maintenance much less. Learning arithmetic or chess requires a lot of effort, but once a certain level of mastery is reached, it remains roughly at that level without further training (unfortunately, this is not the case with physical condition).
We show that the combination of these mechanisms allows a balanced growth of several correlated abilities. Specially chosen parameter settings lead to different patterns of abnormal development (such as hyperspecialization and delayed development). The final model is:
\[ \begin{gathered} \frac{dX_{i}}{dt} = X_{i} (\sum_{j=1}^{V} \mu_{ij} R_j \overbrace{(1- \frac{X_i}{K_i})}^{\text{Logistic growth}} - d_i) + \overbrace{ \sum_{l=1}^{W} M_{il} X_{i} X_{l} / K_{i} }^{\text{Mutualism}}, \\ \frac{dR_{j}}{dt} = r(r_{max}-R_j)- R_j \sum_{i=1}^{W} b_{ij} \begin{cases} \frac{dX_{i}}{dt}, & \text{if growth-dependent depletion} \\ X_{i}, & \text{otherwise} \end{cases} \end{gathered} \tag{6.3}\]
6.3.1.4 The wiring of intelligence
A limitation of mutualism models is that only the activation of nodes is updated. The weight and structure of the network are fixed. While this may be sufficient to explain some developmental phenomena, it is ultimately unsatisfactory. The links themselves should be adaptable, as in the learning of neural networks. An example of learning in the form of updating weights is presented in Section 6.3.3, on the Ising attitude model.
Savi et al. (2019) consider the case where both nodes and links are updated. For example, new facts (1 + 1 = 2) and procedures (addition) are developed in the process of learning arithmetic. Links between these nodes may prevent forgetting. We use the Fortuin—Kasteleyn model, a generalization of the Ising model, in which both nodes and links are random variables. An important property of the model is that whenever two abilities are connected, they are necessarily in the same state,—that is, they are either both present or both absent. It provides a parsimonious explanation of the positive manifold and hierarchical factor structure of intelligence. The dynamical variant suggests an explanation for the Matthew effect, that is, the increase in individual differences in ability over the course of development.
Cognitive growth is a process in which new nodes and links are added during development.
However, it is difficult to create a growing network with Fortuin—Kasteleyn properties. A simple example of this problem is the random network. In random networks, there is a uniform probability that two nodes are connected. But if we add new nodes to such a network and connect them to existing nodes with the same probability, the existing nodes will have more connections on average. Thus, adding new nodes destroys the uniform randomness of the network; that is, the probability that two nodes are connected is not uniform over nodes anymore. Such a network is a non-equilibrium network (Dorogovtsev and Mendes 2002). Rewiring algorithms to achieve equilibrium exist, but they are not trivial.
6.3.2 Symptom networks
In the network perspective on psychopathology, a mental disorder can be viewed as a system of interacting symptoms (figure 6.9). Network theory conceptualizes mental disorders as complex networks of symptoms that interact through feedback loops to create a self-sustaining syndromic constellation (Borsboom 2017).
Mental disorders can be understood as alternative stable states of highly interconnected networks of symptoms.
Like the mutualism model, this is an alternative to the common cause view. Depression could be caused by some malfunction in the brain, a dysregulation of hormones, or even a genetic defect. But, as with general intelligence, no such common cause has yet been found. Drugs work to some extent, but so do most interventions, even placebos and waiting lists (Posternak and Miller 2001). We explicitly offered the network approach as an alternative to the \(p\) factor account of psychopathology (van Bork et al. 2017).3 It is called the \(p\) factor because it is thought to be conceptually parallel to the \(g\) factor of general intelligence (Caspi et al. 2014). And, again, no one seems to know what \(p\) might be.

This lack of theoretical progress encouraged the development of network theory (Cramer et al. 2010; Cramer et al. 2016). As mentioned in the introduction of this chapter, this line of research has become popular. Most of this work consists of data analytic studies. In the simplest case, a questionnaire asking about the severity of symptoms is administered to a group of people, sometimes patients, sometimes a mixture of people who do and do not suffer from a disorder. A variety of psychometric approaches, discussed later in this chapter, are used to fit networks to the data. In this way, one learns to understand the structure of psychopathological networks. It is possible to model comorbidity in this way (Cramer et al. 2010; Jones, Ma, and McNally 2021). In the case of major depression and generalized anxiety disorder, sleep problems seem to be a typical bridge symptom (Blanken et al. 2018).
Comorbidity is modeled by bridging symptoms between network clusters.
The most popular application is to detect which symptoms are central to a disorder (Fried et al. 2016). However, centrality analysis based on cross-sectional data has its limitations (Bringmann et al. 2019; Spiller et al. 2020). This is one reason to focus on individual networks using time-series data, often obtained in experience sampling methods. Again, these techniques are still under development and not without problems (Dablander and Hinne 2019; Haslbeck and Ryan 2022). For a review of the network approach to psychopathology, see Robinaugh et al. (2020).
In terms of building actual models, not as much work has been done. In Cramer et al. (2016), we proposed an Ising-type model, with node values of 0 and 1, representing symptoms being on or off. Nodes were turned on and off based on a probability computed with a logistic function \(P = 1/(1 + e^{b_{i} - A_{i}^{t}})\). \(A_{i}^{t}\) equals the sum of the weighted input from other connected nodes, and \(b_{i}\) is a node-specific threshold that normally keeps nodes in the 0 state. A strong point of this model is that the connections and thresholds were estimated from data. This model is the origin of the connectivity hypothesis. High connectivity within a network of symptoms could lead to a more persistent and severe disorder (for a discussion, see Elovainio et al. 2021).
The connectivity hypothesis suggests that the strength of these connections may lead to the development and maintenance of the disorder.
Since thresholds are generally negative (the 0 state of nodes is the default state), sufficient connectivity is required to have a depression as an alternative stable state. A limitation of this model is that although it is related to the Ising model, the exact dynamics are not well understood.
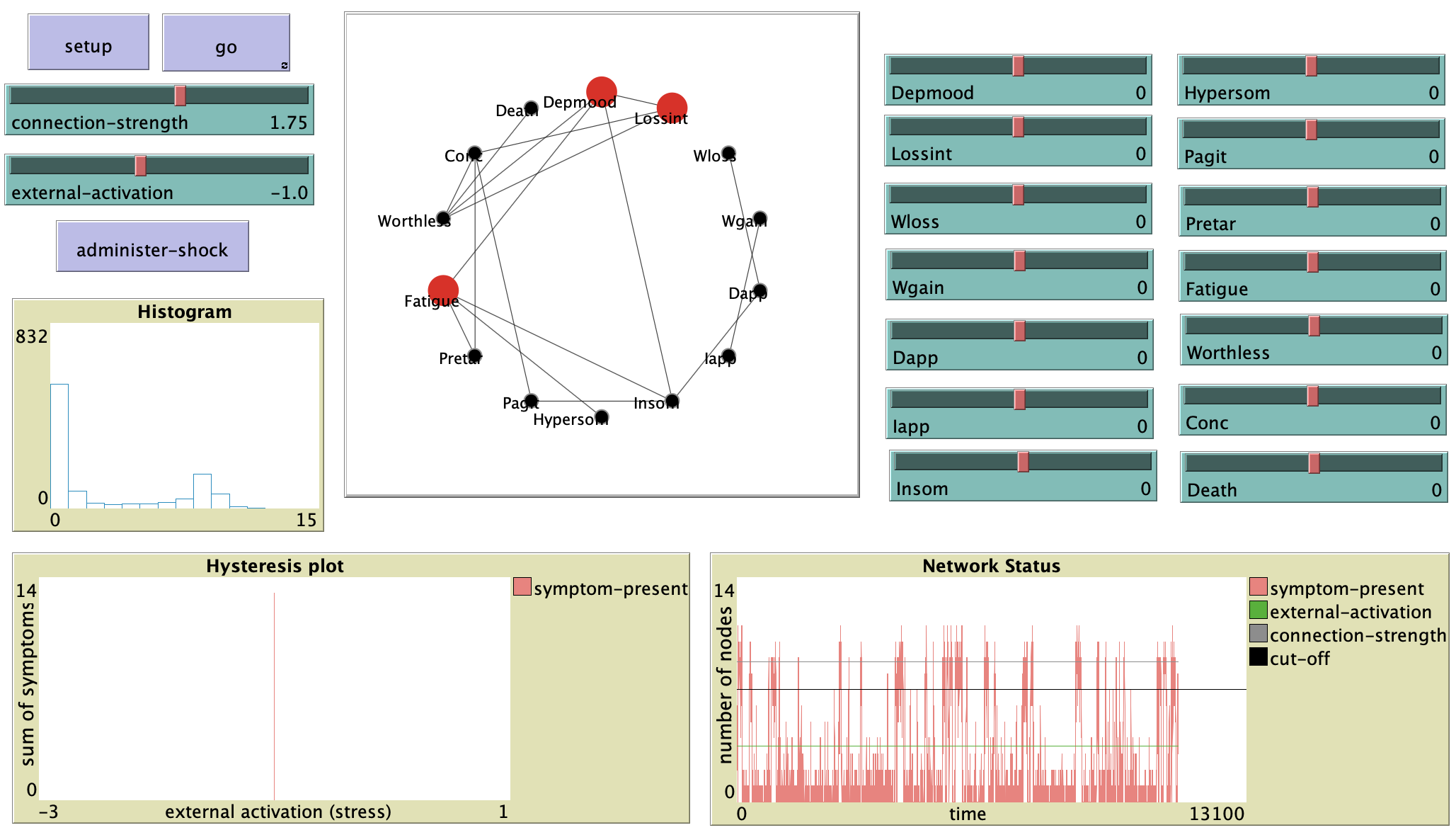
A similar approach was used by Lunansky et al. (2022) in order to define resilience and evaluate intervention targets. You can see this in the NetLogo “Vulnerability to Depression” model (see figure 6.10). Another relevant network modeling approach, based on causal loop diagrams, is proposed in Wittenborn et al. (2016).
Resilience is the ability of a system to recover from perturbations and maintain its current equilibrium.
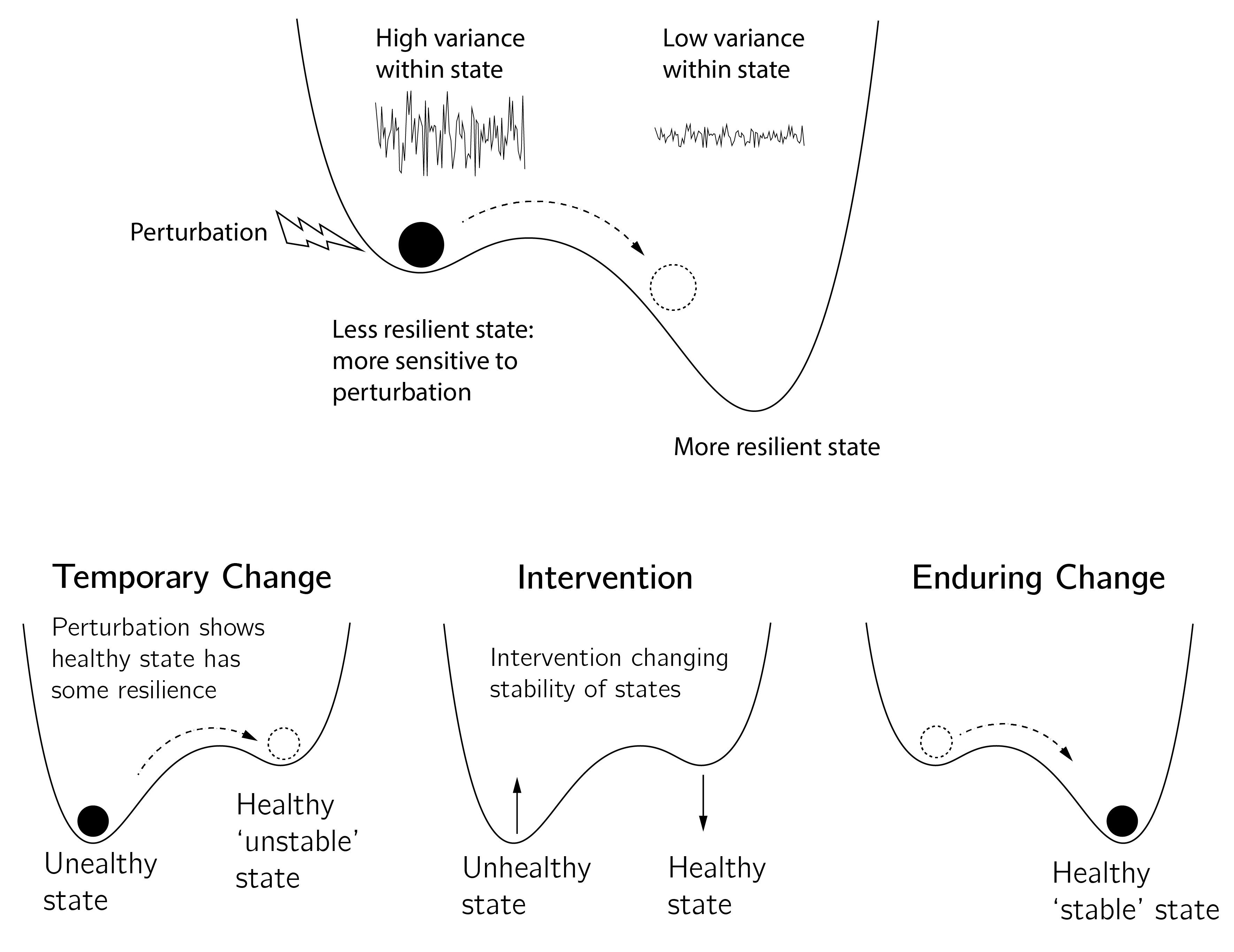
The connection to resilience is interesting. In dynamic terms, resilience is associated not with the healthy or unhealthy state but with the stability of these states (Kalisch et al. 2019). In Section 3.3.3 the less deep minimum is called the metastable state. These states have less resilience than the globally stable state (figure 6.11).
This suggests a distinction between perturbations and interventions. With interventions, we change the equilibrium landscape to allow a sustainable change to a healthy state. Perturbations (a brief intervention or a positive or negative event) can have a permanent or temporary effect, depending on which state is more resilient. In the situation shown in the top panel of figure 6.11, any perturbation, whether it is a treatment or an alternative (or even being on the waiting list), will work. In the situation on the bottom left, no intervention would have a lasting effect. This analysis of resilience may help to understand the inconsistent results of studies of intervention effects. Monitoring the resilience of the unhealthy state (with catastrophe flags such as anomalous variance) may also be important for timing interventions (Hayes and Andrews 2020). Failed interventions, such as an attempt to quit smoking, are likely to reinforce the unhealthy state (Vangeli et al. 2011).
6.3.3 Ising attitude model
The network approach has been applied to many other domains outside of intelligence research and the study of psychopathology. Examples include emotion (Lange and Zickfeld 2021; Treur 2019), personality (Costantini et al. 2015; Cramer et al. 2012), interest (Sachisthal et al. 2019), deviations of rational choice (Kruis et al. 2020), and organizational behavior (Lowery, Clark, and Carter 2021). One area where it has been developed into a new theory is attitude research.
People have many attitudes—about food, politics, other people, horror movies, the police, etc. They help us make decisions and guide our behavior. Attitudes can be very stable and multifaceted, but they can also be inconsistent and inconsequential. Social psychology has studied attitudes for a long time, and many insights and theories have been developed.
The formalization of attitude theories has been dominated by the connectionist account (Monroe and Read 2008; Van Overwalle and Siebler 2005). In connectionist models, developed in the parallel distributed processing (PDP) framework, attitude units (e.g., beliefs) form a connected network whose activations (usually between \(-1\) and \(1\)) are updated based on the weighted sum of internal inputs from other units and an external input. These weights or connections are updated according to either the delta rule (a supervised learning rule based on the difference between the produced and expected output of the network) or the Hebb rule. With this setup, these models can explain a number of phenomena in attitude research. Another network account has been put forward in sociology (DellaPosta 2020).
Attitudes are complex constructs. Typical phenomena, such as cognitive dissonance, imbalance, ambivalence, and political polarization, can be well described by a network model.
In this section, I will discuss our network approach to attitudes using the Ising model, which was developed in a series of recent papers. The advantages of this model over the connectionist PDP models are that it is derived from basic assumptions, is better understood mathematically, is easy to simulate, provides a psychological interpretation of the temperature parameter, and can be fitted to data (Dalege et al. 2017).
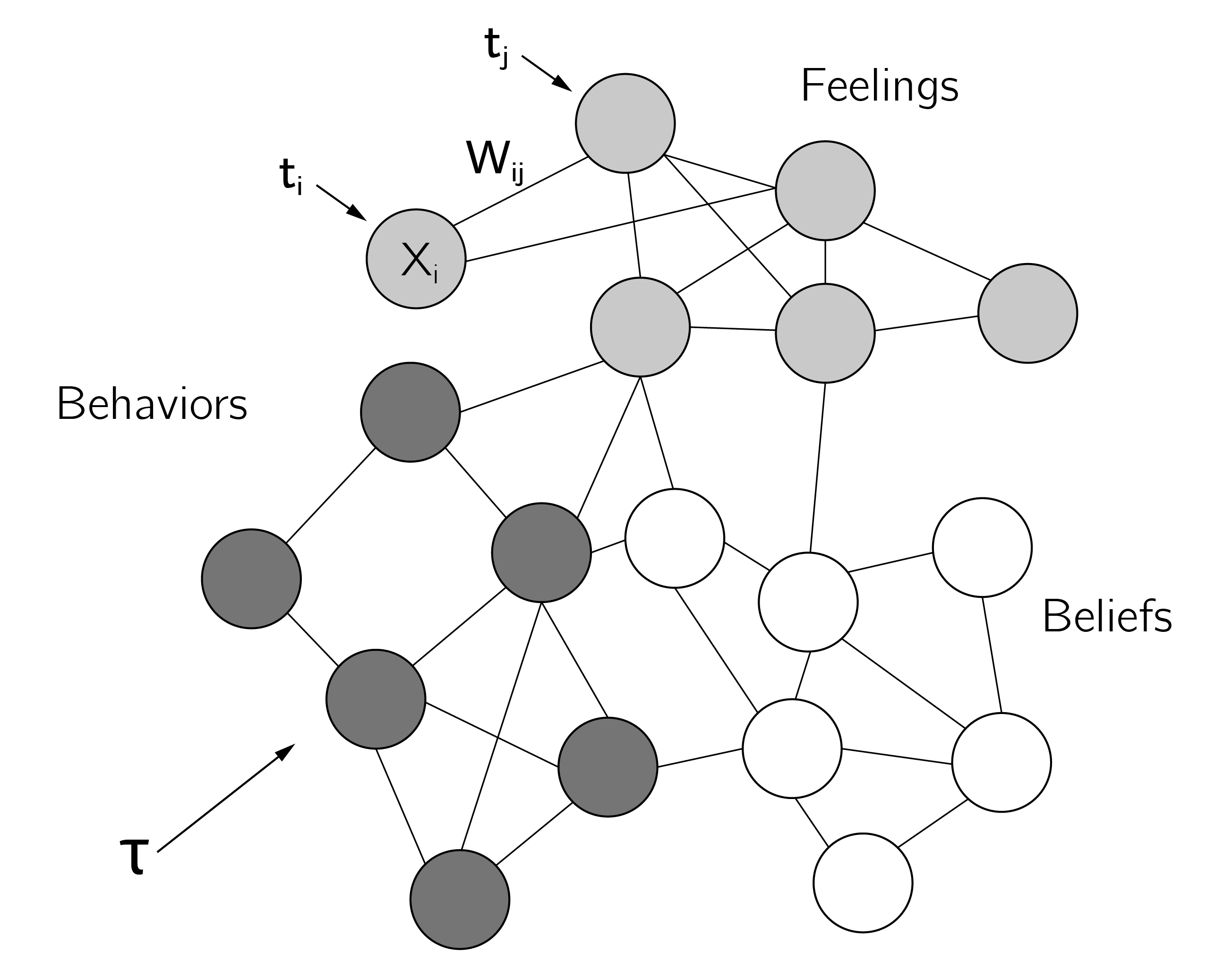
The Ising model was developed as an alternative to the tripartite factor model of attitudes, in which the attitude, a latent factor, consists of lower-order cognitive, affective, and behavioral factors that each explain observed responses, similar to the Cattell—Horn—Carroll model of general intelligence. The causal attitude model (Dalege et al. 2016) maintains this distinction in cognitive, affective, and behavioral components, but now conceptualizes them as clusters within a network. Nodes represent single feelings, beliefs, and behaviors. In Dalege et al. (2018), this network model is formalized in the form of an Ising model with attention as the equivalent of (the inverse of) temperature. That is, high attention “freezes” the network and leads to consistent and stable positive or negative states of the attitude (the “mere thought effect”).
Attitudes are networks of feelings, beliefs, and behaviors toward an attitude object.Attention is equated to (inverse) temperature.
6.3.3.1 Model setup
The basic assumptions of the Ising attitude model are that nodes are binary (e.g., one eats red meat or not), that nodes influence each other causally, and that they have specific thresholds (as in the model for depression). An external field (a campaign to eat less meat) could also affect the nodes. The alignment of nodes to other nodes and to the external field depends on one’s attention, \(A\), to the attitude object.
Given these simplifying assumptions, which can be relaxed in various ways, we arrive at the random field Ising model (Fytas et al. 2018). This model is not too different from the Ising model described in Chapter 5, Section 5.2.1, except that the first term now has two components, a general external effect (\(\tau\)) and an effect of node-specific (\(t_{i}\)) thresholds (“I just really like the taste of chicken”). The random field Ising attitude model can then be defined as:
\[\begin{array}{r} H\left( \mathbf{x} \right) = - \sum_{i}^{n}{(\tau + {t_{i})x}_{i}} - \sum_{<ij>}^{}{{W_{ij}x}_{i}x_{j}}, \end{array} \tag{6.4}\]
\[\begin{array}{r} P\left( \mathbf{X} = \mathbf{x} \right) = \frac{\exp\left( - AH\left( \mathbf{x} \right) \right)}{Z} \end{array}. \tag{6.5}\]
Another difference from the original Ising model introduced in Chapter 5 is that the interactions are now weighted and can even be negative. The main technical problem is the same. To compute the probability of a state, one has to compute \(Z\), which is \(\sum_{< \mathbf{x} >}^{}{exp(- AH\left( \mathbf{x} \right))}\), that is, a sum over all possible states (\(2^{n}\)). For large values of \(n\), this is not feasible. One solution is to take a random initial state and use Glauber dynamics to update the states until an equilibrium state is reached. The Glauber algorithm does not require \(Z\). There are faster but less intuitive algorithms, the most popular being the Metropolis—Hastings algorithm, which slightly modifies the Glauber dynamics presented in Chapter 5, equation 5.3.
As discussed in Chapter 5 (Section 5.2.1), another approach to understanding the dynamics of Ising-type models is the mean-field approximation. This requires the assumption that the network is fully and uniformly connected with equal thresholds (known as the Curie—Weiss model). In this approximation \(W_{ij} = c\) (all equal) and \(x_{j}\) are replaced by their mean values, which greatly simplifies the energy function. It can be shown that the dynamics of the simple fully connected Ising model are well approximated by the cusp, with the external field as normal and the inverse temperature as the splitting variable.
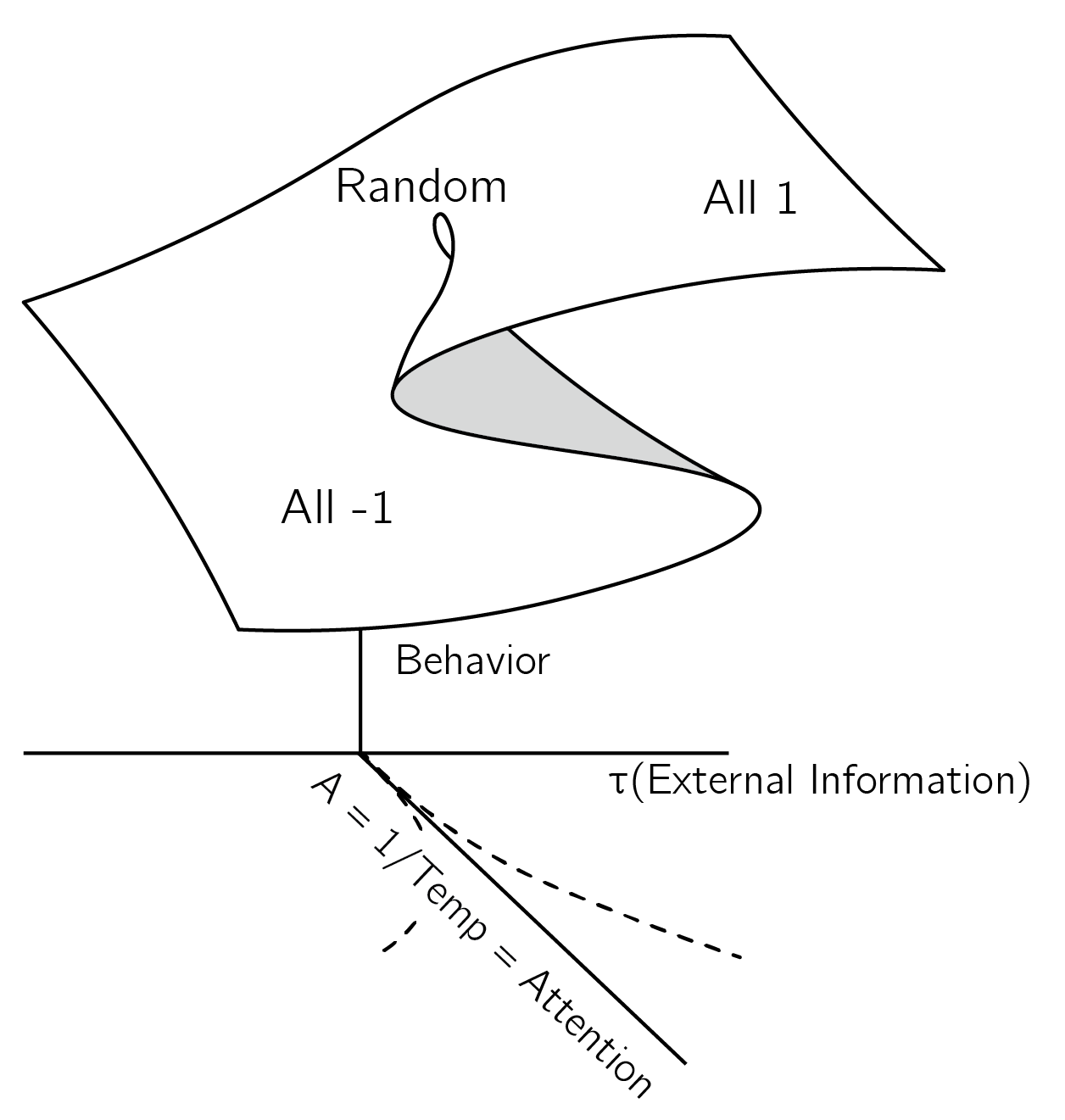
This is an important result because it makes the use of the cusp in attitude research (see figure 3.13) less phenomenological. The cusp is now derived from more basic principles (figure 6.13). Note that here we use attention as the splitting variable, whereas in Chapter 3 we used involvement. These are closely related concepts, the difference being the time scale. Attention can change in seconds or minutes, whereas involvement can change in weeks or months. I will use attention and involvement interchangeably.
This mean-field approximation is very robust. In van der Maas, Dalege, and Waldorp (2020), we show via simulation that networks with fewer connections and a distribution of weights, some of which are negative, are still well described by the cusp. This can be easily checked with some R code or in NetLogo. We will make use of the IsingSampler package in R.
6.3.3.2 Simulation
The IsingSampler function runs the Metropolis—Hastings algorithm \(nIter\) times and returns the last state. It can return multiple final states for \(N\) runs. As input, it takes a matrix of links (\(\mathbf{W}\)), which for the Curie—Weiss model should be constant with 0s on the diagonal. The thresholds for each node should be equal. Beta, originally the inverse of the temperature (\(1/T\)), represents attention. The effect of varying beta (attention) is shown in figure 6.9.
library("IsingSampler")
n <- 10 # nodes
W <- matrix(.1, n, n); diag(W) <- 0
tau <- 0
N <- 1000 # replications
thresholds <- rep(tau, n)
layout(t(1:2))
data <- IsingSampler(N, W, nIter = 100, thresholds,
beta = .1, responses = c(-1, 1))
hist(apply(data, 1, sum), main = "beta = .1", xlab = 'sum of x')
data <- IsingSampler(N, W, nIter = 100, thresholds,
beta = 2, responses = c(-1, 1))
hist(apply(data, 1, sum), main = "beta = 2", xlab = 'sum of x')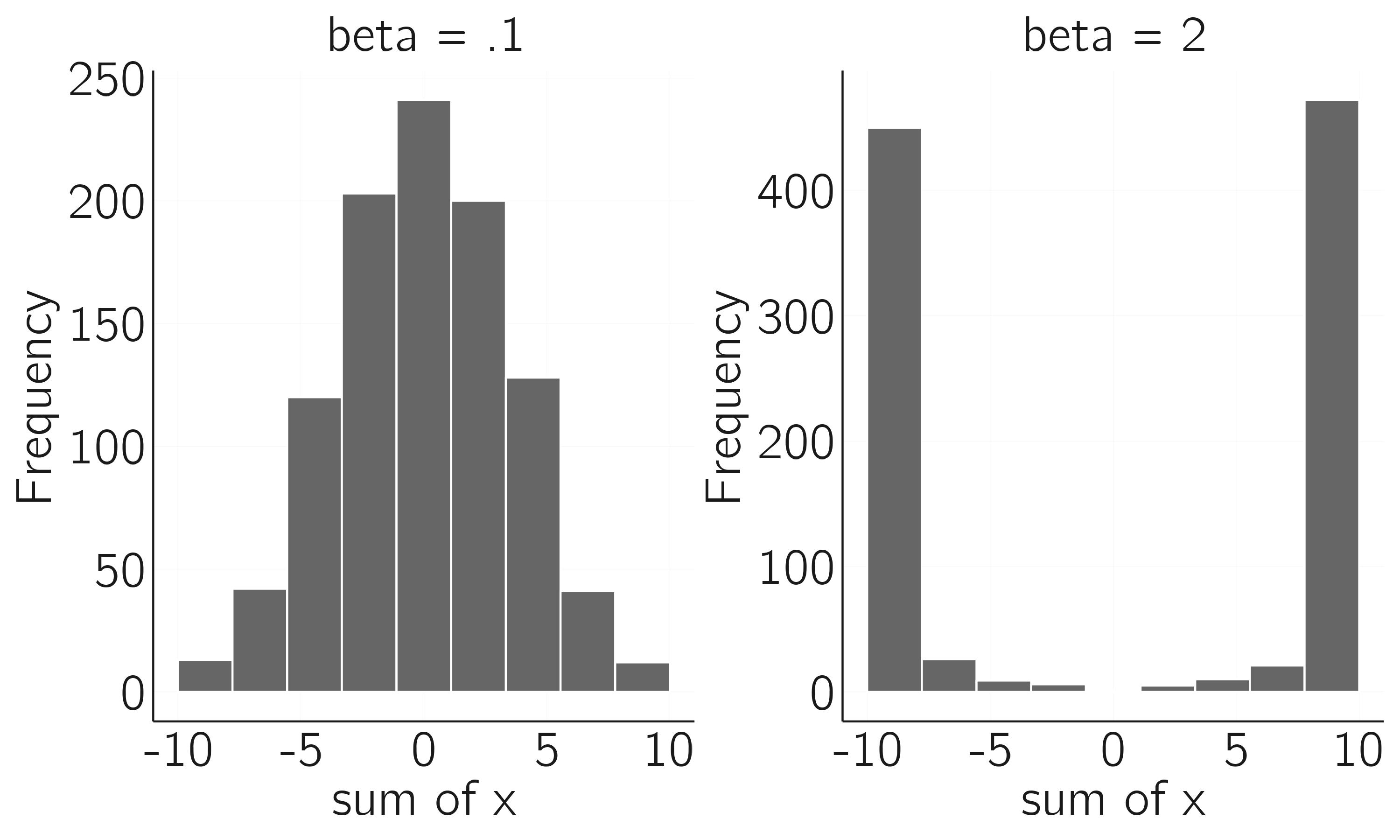
In Dalege and van der Maas (2020), we simulated the difference between implicit and explicit measures of attitude. The idea is that the individual thresholds contain information about the attitude that can only be detected when attention is moderately low. When attention is too high, the alignment between the nodes dominates the thresholds (figure 6.15). Indeed, in implicit (indirect) measures of attitude, attention is much lower than in explicit measures such as an interview. This can be simulated as follows:
layout(1)
N <- 400; n <- 10
W <- matrix(.1, n, n); diag(W) <- 0
thresholds <- sample(c(-.2, .2), n,
replace = TRUE) # a random pattern of thresholds
dat <- numeric(0)
beta.range <- seq(0, 3, by = .05)
for(beta in beta.range){
data <- IsingSampler(N, W, nIter = 100, thresholds,
beta = beta, responses = c(-1, 1))
dat <- c(dat, sum(thresholds * apply(data,2,sum))) # measure of alignment
}
plot(beta.range, dat, xlab = 'beta', ylab = 'alignment with thresholds',
bty = 'n')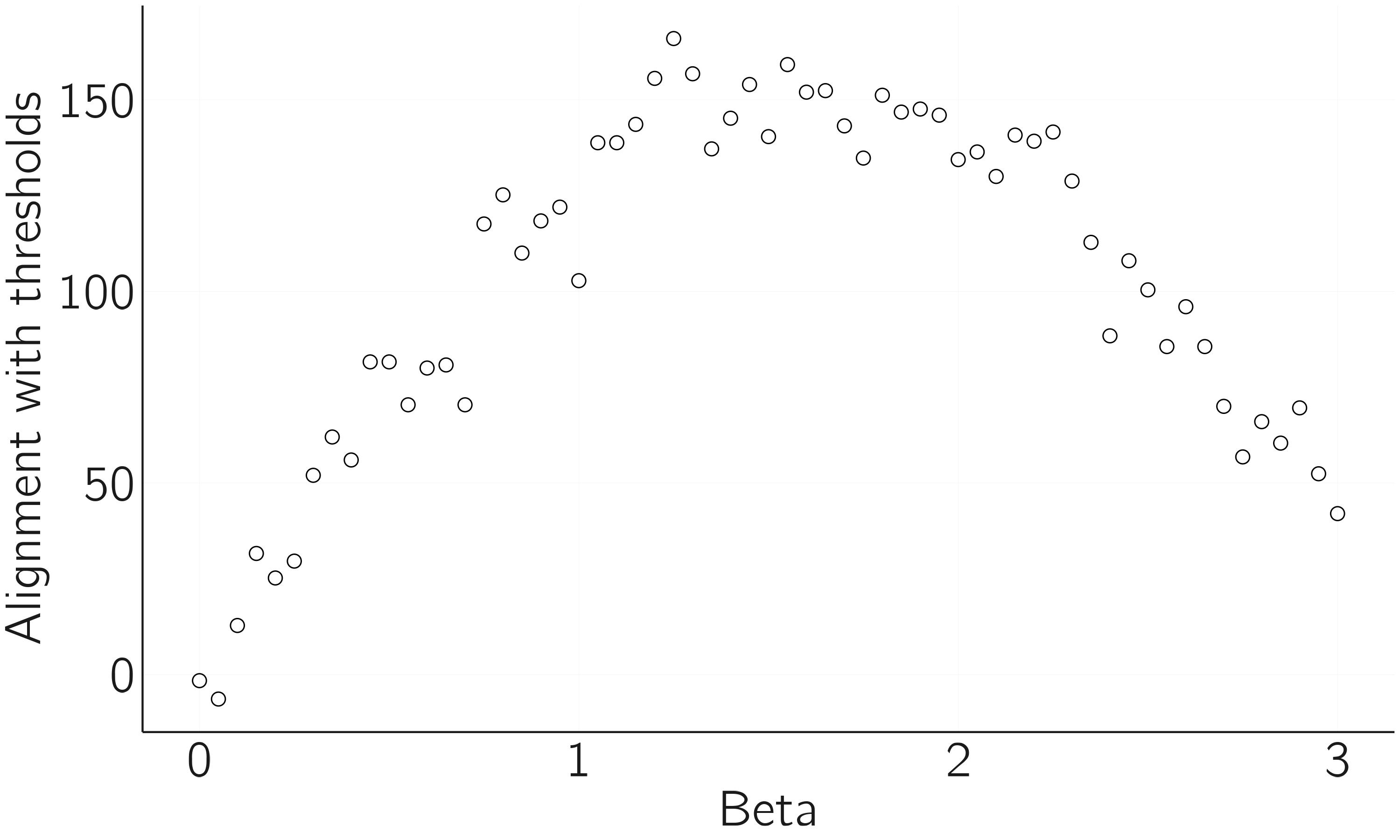
We see that for medium attention, the agreement with the thresholds is highest. When attention is 0 or very low, nodes behave randomly and do not correlate with the thresholds. When attention is very high, the effects of node-specific thresholds are masked by the collective effects of other nodes. The principal problem of implicit measurement is that for low to medium attention, the network is quite noisy and measurement reliability will be low. This is why this paper is called “Accurate by Being Noisy.”
6.3.3.3 Learning
The connectionist attitude models are capable of “learning,” that is, adjusting the weights. This can also be done in the Ising attitude model by using Hebbian learning. Hebbian learning, or “what fires together, wires together,” can be formulated as:
\[\begin{array}{r} \mathrm{\Delta}W_{ij} = \epsilon\left( 1 - \left| W_{ij} \right| \right)x_{i}x_{j} - \lambda W_{ij}, \end{array} \tag{6.6}\]
which defines the change in weights. Weights will grow to \(1\) if the nodes they connect are consistently either both \(1\) or both \(-1\). If they consistently differ in value, the weight grows to \(-1\). If the nodes behave inconsistently, the weight shrinks to \(0\), due to the last term.
In R, this can be implemented as follows:
library(qgraph)
hamiltonian <- function(x, n, t, w){
-sum(t * x) - sum(w * x %*% t(x)/2)
}
glauber_step <- function(x, n, t, w, beta){
i <- sample(1:n, size = 1) # take a random node
# construct new state with flipped node:
x_new <- x; x_new[i] <- x_new[i] * -1
# update probability
p <- 1/(1 + exp(beta * (hamiltonian(x_new, n, t, w) -
hamiltonian(x, n, t, w))))
if(runif(1) < p) x <- x_new # update state
return(x)
}
layout(t(1:2))
epsilon <- .002; lambda <- .002 # low values = slow time scale
n <- 10; W <- matrix(rnorm(n^2, .0, .4), n, n)
W <- (W + t(W)) / 2 # make symmetric
diag(W) <- 0
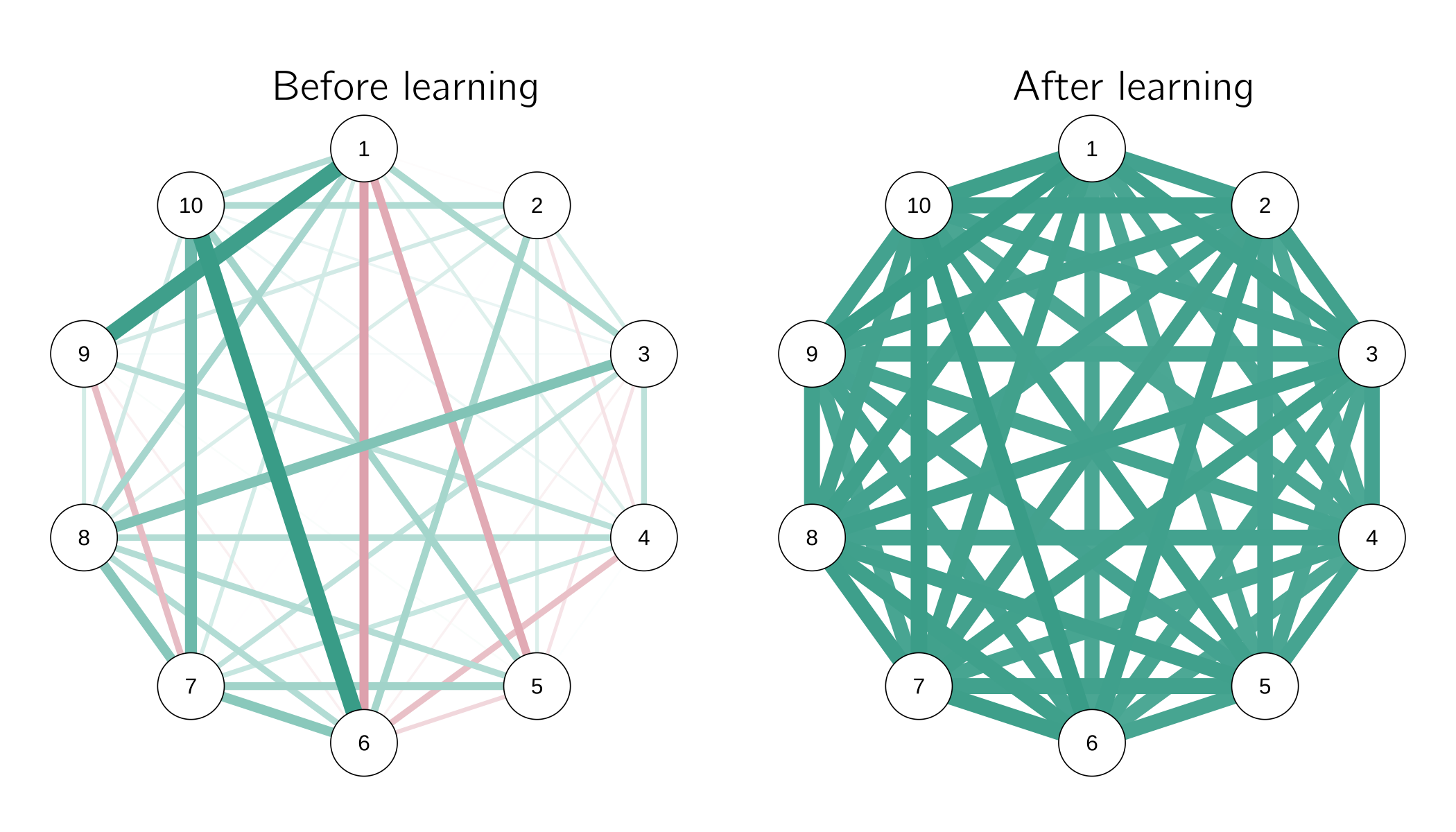
qgraph(W); title('before learning')
thresholds <- rep(.2, n)
x <- sample(c(-1, 1), n, replace = TRUE)
for(i in 1:500){
x <- glauber_step(x, n, thresholds, W, beta = 2)
# Hebbian learning:
W <- W + epsilon * (1 - abs(W)) * outer(x, x, "*") - lambda * W
diag(W) <- 0
}
# label switching (scale all nodes to positive):
W <- x * t(x * W); x <- x * x
qgraph(W); title('after learning')Figure 6.16 shows the result of this simulation.
In this case we want to update the nodes values using the Glauber dynamics (equation 5.3), which use the computation of the energy of a particular state. Both functions (glauber_step() and hamiltonian()) are added to the R code.
Due to Hebbian learning, a network evolves from an unbalanced network (random connections) to a consistently balanced network. Without learning, we need high attention to make the attitude network behave consistently. In the learning Ising attitude model (LIAM), weights increase during periods of high attention. The advantage is that in later instances, less attention is required for consistent network behavior (Smal, Dalege, and Maas submitted). In this way we can develop stable attitudes that do not require much attention to be consistent.
Developing strong, balanced attitudinal networks has a clear advantage: they do not require much attention to be consistent.
6.3.3.4 The stability of attitudes and entropy measures
To quantify the consistency of attitudes, we can compute the Gibbs entropy (proposition I.2 in Dalege et al. 2018). The Boltzmann entropy was defined in Section 5.2.1 as the log of the number of ways (\(W\)) a particular macrostate can be realized. It measures the inconsistency of a particular attitude state (proposition I.1 in Dalege et al. 2018).4 Gibbs entropy is more general in that it does not assume that each microstate is equally probable. It is defined as:
Gibbs entropy describes the probability distribution over the different microstates \(\mathbf{x}\).
\[\begin{array}{r} - \sum_{< \mathbf{x} >}^{}{P\left( \mathbf{x} \right)\ln{P\left( \mathbf{x} \right)}}. \end{array} \tag{6.7}\]
Note that we sum over all microstates (\(2^{n})\). For small networks, this measure can be computed using the IsingEntrophy() function of the IsingSampler package. There is much more to say about the different entropy measures. For instance, Shannon entropy (a measure in information theory) and Gibbs entropy have the same mathematical definition but are derived from completely different lines of reasoning in different fields of science. An introduction to the discussion on entropy measures can be found at the Entropy page of Wikipedia.
6.3.3.5 Tricriticality
A new direction of research concerns Ising-type models with trichotomic node values (\(—1 ,0 , 1\)). In physics this case is known as the tricritical Ising model or the Blume—Capel model (Saul, Wortis, and Stauffer 1974). In physics, the states \(-1\) and \(1\) could represent the spin of a particle pointing up or down, while \(0\) could represent a nonmagnetic or spinless state. In an attitude model, \(-1\) and \(1\) may represent pro and con beliefs, while \(0\) represents a neutral belief. The Hamiltonian of the model includes a penalty for the \(-1\) and \(1\) states:
\[\begin{array}{r} H\left( \mathbf{x} \right) = - \sum_{i}^{n}{\tau x_{i}} - \sum_{< i,j >}^{}{x_{i}x_{j}} + D\sum_{i}^{n}{x_{i}}^{2}. \end{array} \tag{6.8}\]
You can compare this to equation 5.1. The last term penalizes (increases the energy) of the \(-1\) and \(1\) states relative to the \(0\) state.
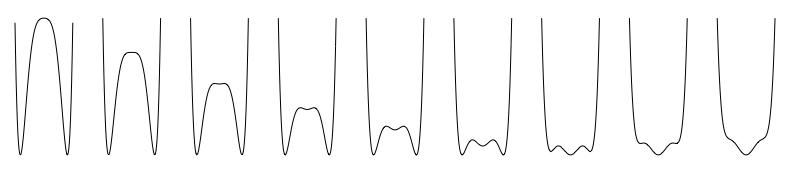
The dynamics of this model are more complicated. It resembles the butterfly catastrophe (Dattagupta 1981), which has a tricritical point. The potential function, \(V(X) = {- aX - \frac{1}{2}bX^{2} - \frac{1}{3}cX^{3} - \frac{1}{4}dX^{4} + \frac{1}{6}X}^{6}\), has three stable fixed points for specific combinations of values of parameters (see Section 3.3.5 and the exercise about the butterfly catastrophe in that chapter). This is relevant to the modeling of attitudes because it opens up the possibility of involved stable in-between attitude positions (see figure 6.17). The Ising attitude model excludes this.
In the Ising attitude model highly involved persons always radicalize, but more advanced spin models allow for involved nonpartisan positions.
6.4 Psychometric network techniques
So far, we have seen examples of theoretical psychological network models in the fields of cognitive, clinical, and social psychology. However, much of the popularity of such models is due to the psychometric approach developed to analyze data using networks. In the last fifteen years, a family of statistical approaches has been developed for all kinds of data and empirical settings. Our psychosystems group (psychosystems.org) has published a book called Network Psychometrics with R: A Guide for Behavioral and Social Scientists (Isvoranu et al. 2022). This resource is highly recommended. I will limit myself to a brief overview and some practical examples related to the models presented in the first part of this chapter.
6.4.1 Main techniques
An important aspect of Network Psychometrics is visualizing the network—the process of creating visual representations of the network structure. This helps in interpreting the data. The main R packages for visualization are igraph and qgraph. Both packages include many useful functions.
A more advanced application of network psychometrics is network estimation. The most widely used methods for network estimation are Gaussian graphical models (packages bgms, BDgraph, ggm, psychonetrics, qgraph, BGGM, huge), partial correlation networks (qgraph, qgraphicalmodels), and Ising models (IsingFit, IsingSampler, rbinnet). The mgm package can be used to fit mixed graphical models with a mixture of categorical and continuous valued nodes. The bgms package applies Bayesian estimation and allows testing for missing links. The huge package is used to represent the conditional dependence structure among many variables and is particularly useful when the number of variables is much larger than the sample size.
Network estimation uses statistical methods to estimate the networkstructure, including which nodes are connected to each other and the strength of those connections.
The estimation is usually followed by a centrality analysis. The most important nodes in the network are identified based on their degree of centrality, which measures the extent to which a node is connected to other nodes in the network. Centrality measures include degree centrality, betweenness centrality, bridge centrality, and eigenvector centrality, among others (packages psych, networktools).
Another important step is network comparison. This can be done using techniques such as the network permutation test, bootstrapping, and moderation analysis (R packages bootnet and NetworkComparisonTest).
Network comparison is the process of comparing the structure of two or more networks to determine if they are significantly different from each other.
We can perform network inference, inferring causal relationships between nodes, when we have time-series data or when we have intervened in the network. Depending on the type of time series (\(N=1\) time series, \(N>1\) time series, panel data), different modeling options and packages are available (packages psychonetrics, mgm, graphicalVar, mlVar). GVAR returns a temporal network, which is a directed network of temporal relationships, and a contemporaneous network, which is an undirected network of associations between the variables within the same time frame after controlling for temporal relationships.
Time-series network inference involves analyzing sequential data to identify patterns of interactions and dependencies among variables.
For a detailed discussion of the reasons for using certain techniques, I again refer you to our recent book. The brief overview I have provided here may soon be obsolete. The CRAN Task View: Psychometric Models and Methods will give you an up-to-date overview.5 Another option is to use JASP.6 JASP is a free, open-source statistical analysis program developed under the supervision of Eric Jan Wagenmakers (Huth et al. 2023; Love et al. 2019). It is a user-friendly interface for accessing R packages. Many of the network R packages mentioned above are available in JASP.7
All major statistical analyses, both frequentist and Bayesian, are available in JASP.
Finally, I mention semantic network analysis again. A review of statistical approaches (available in R) is provided by Christensen and Kenett (2021).
6.4.2 Fitting the mutualism model
In Section 6.3.1.2, I provided code to simulate data. These data can be fitted using JASP. By rerunning the previous code and adding
write.table(file='mutualism.txt', data, row.names = FALSE, sep='\t')we have a data file ready to analyze in JASP.
After opening this file in JASP, you will see the data. In the Network (Frequentist) tab, select all variables and the EBICglasso option. EBICglasso is an R function from the qgraph package. It calculates the Gaussian graphical model and applies the LASSO regularization to shrink the estimates of links to 0 (Friedman, Hastie, and Tibshirani 2008). This prevents the presence of many irrelevant links without losing predictive value. Alternatively, one could use significant testing or a Bayesian procedure. In JASP, one could use the partial correlation option. I recommended playing around with some options and inspecting additional plots.
Mutualism is an alternative explanation for the positive manifold, which means that the fit of a factor model to such data does not prove that the \(g\) factor theory is correct. It can be shown (van der Maas et al. 2006) that the simple mutualism factor model with all \(M_{ij} = c\), is equivalent to the one-factor model. This can be tested in JASP by fitting an exploratory one-factor model to the simulated data. The factor loadings should all be very similar.
As discussed, cross-sectional networks do not provide information about the direction of effects. We can illustrate this as follows.
M[,1] <- .2 # strong influence of X1 on all others
M[2,] <- .2 # strong influence on X2 by all others
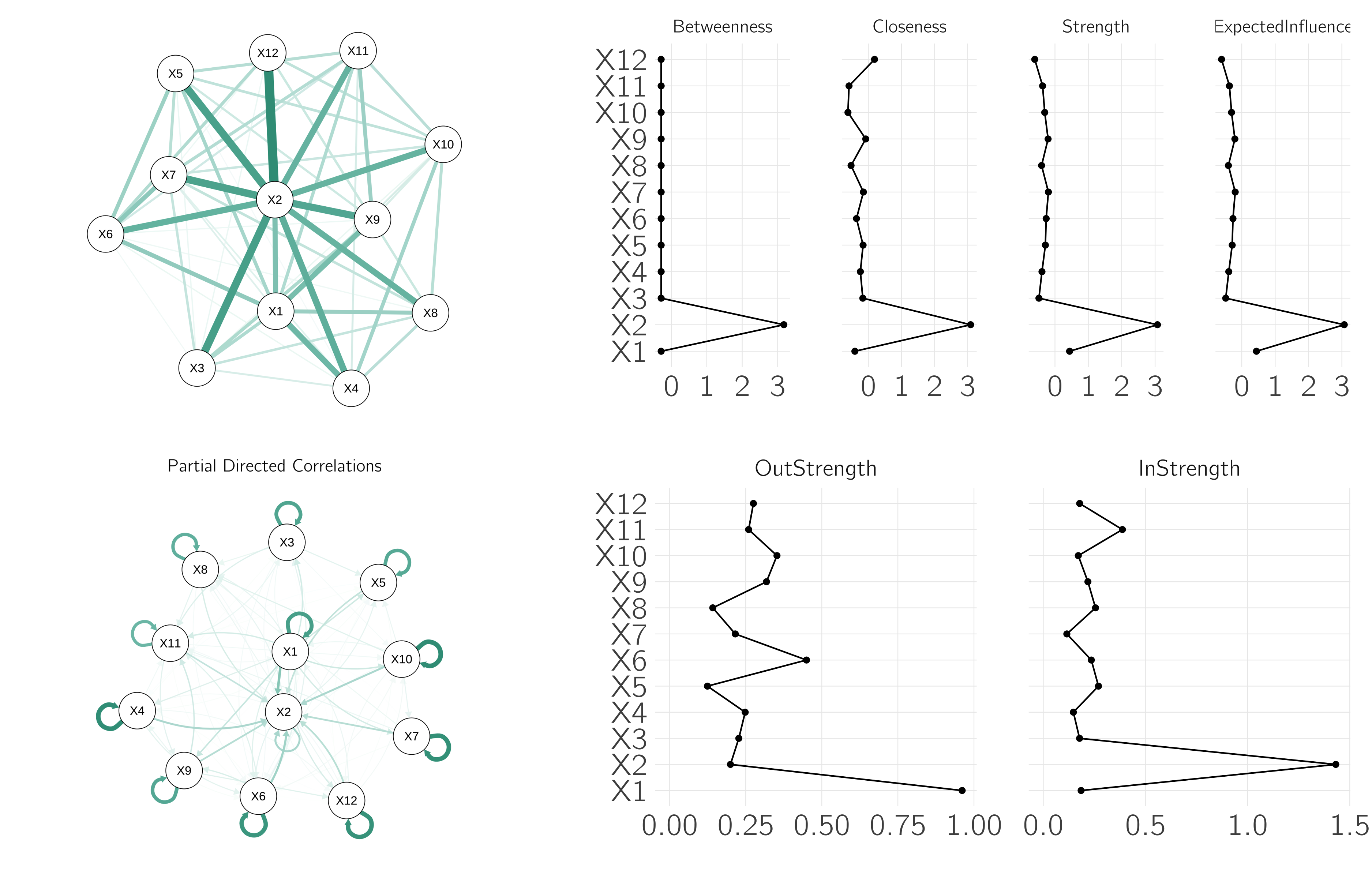
M[diag(nr_var) == 1] <- 0 # set diagonal of m to 0If we rerun the code and create a centrality plot in JASP, we will see the risks of centrality analysis in cross-sectional networks. Node 2 is the most central, but we know from the simulation that this is because it is influenced by all the others. The node with the most causal power (node 1) does not turn out to be an important central node. With time-series data, we can estimate the direction of the effects. We do this in R:
library("graphicalVAR")
# make time series for one persons with some stochastic effects
data <- run(odes = mutualism, tmax = 1000, table = TRUE,
timeplot = (i == 1), legend = FALSE,
after = "state<-state+rnorm(nr_var,mean=0,sd=1);
state[state<0]=.1")
data <- data[,-1]
colnames(data) <- vars <- paste('X', 1:nr_var, sep = '', col = '')
fit <- graphicalVAR(data[50:1000,], vars = vars, gamma = 0, nLambda = 5)
plot(fit, "PDC")
centralityPlot(fit$PDC)The results are shown in figure 6.18. Only the time-series approach provides useful information about possible causal effects.
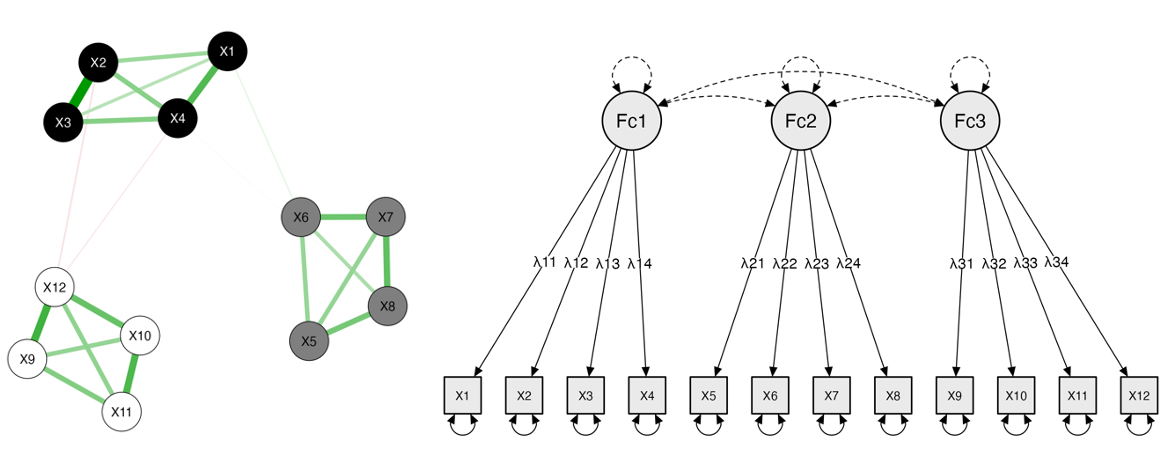
The M-matrix can take different forms. The typical multifactor structure can be achieved with a block structure.
set.seed(1)
factors <- 3
M <- matrix(0, nr_var, nr_var)
low <- .0; high <- .1 # interaction between and within factors
# loop to create M
cat <- cut(1:nr_var, factors)
for(i in 1:nr_var) {
for (j in 1:nr_var) {
if (cat[i] == cat[j])
M[i, j] <- high else M[i, j] <- low
}
}
M[diag(nr_var) == 1] <- 0 # set diagonal of m to 0In JASP, you can perform network and confirmatory factor analysis. In the latter case, select “3 factors” in the first window and select “assume uncorrelated factors” in the model options. The resulting plots should look like figure 6.19.
6.4.3 Fitting Ising models
With IsingFit we can easily fit cross-sectional data generated with the Ising attitude model. Figure 6.20 shows a good fit of the model. The code for this analysis is:
library("IsingSampler"); library("IsingFit")
set.seed(1)
n <- 8
W <- matrix(runif(n^2, 0, 1), n, n); # random positive matrix
W <- W * matrix(sample(0:1, n^2, prob = c(.8, .2),
replace = TRUE), n, n) # delete 80% of nodes
W <- pmax(W, t(W)) # make symmetric
diag(W) <- 0
ndata <- 5000
thresholds <- rnorm(n, -1, .5)
data <- IsingSampler(ndata, W, thresholds, beta = 1)
fit <- IsingFit(data, family = 'binomial', plot = FALSE)
layout(t(1:3))
qgraph(W, fade = FALSE); title("Original network", cex.main = 2)
qgraph(fit$weiadj, fade = FALSE); title("Estimated network", cex.main = 2)
plot(thresholds, type = 'p', bty = 'n', xlab = 'node',
ylab = 'Threshold', cex = 2, cex.lab = 1.5)
lines(fit[[2]], lwd = 2)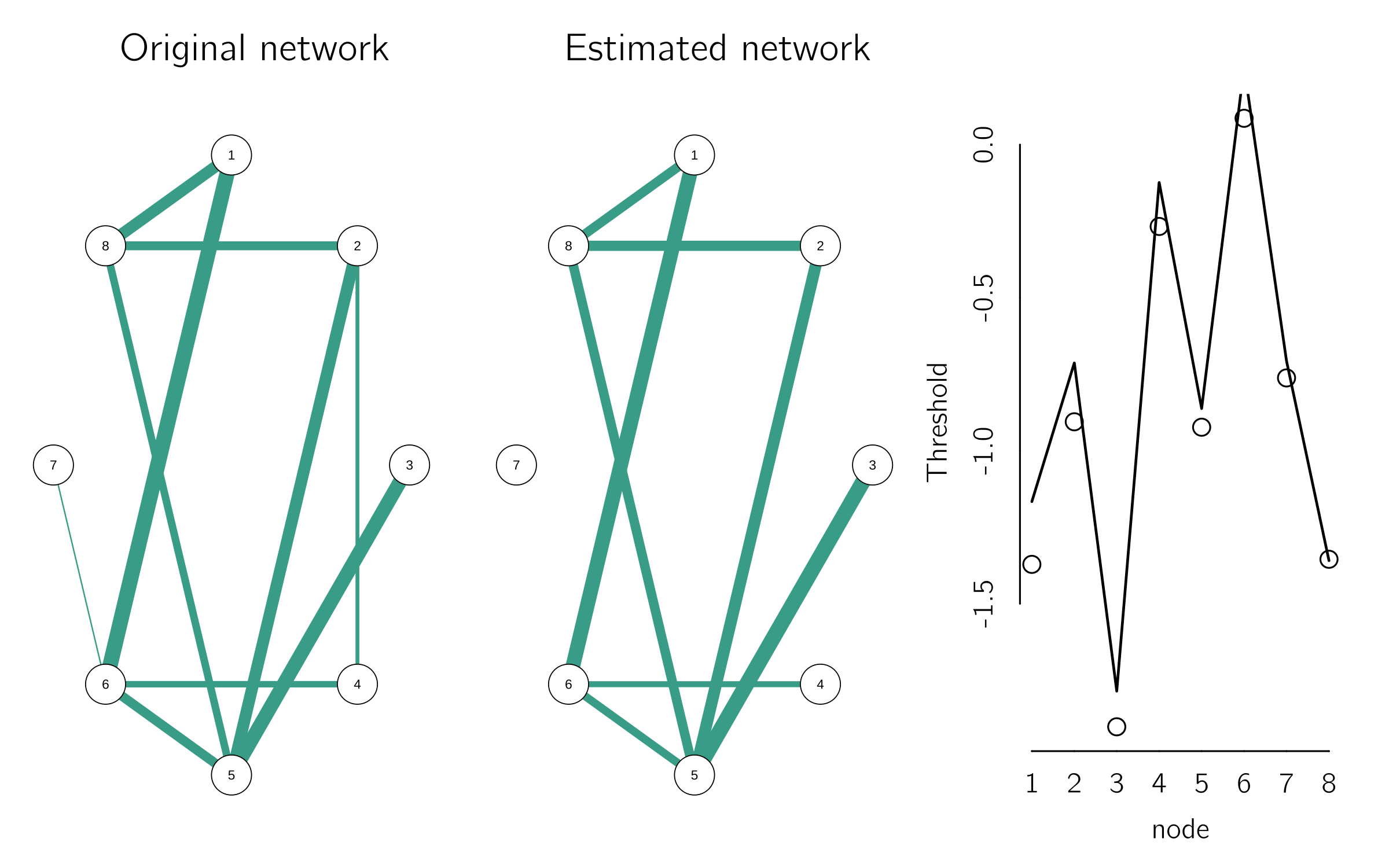
An empirical example is provided in Dalege et al. (2017). The open-access data (\(N = 5728\)) come from the American National Election Study of 2012 on evaluative reactions toward Barack Obama. The items and abbreviations are:
| Items tapping beliefs | Abbreviation |
|---|---|
| “Is moral” | Mor |
| “Would provide strong leadership” | Led |
| “Really cares about people like you” | Car |
| “Is knowledgeable” | Kno |
| “Is intelligent” | Int |
| “Is honest” | Hns |
| Items tapping feelings | |
| “Angry” | Ang |
| “Hopeful” | Hop |
| “Afraid of him” | Afr |
| “Proud” | Prd |
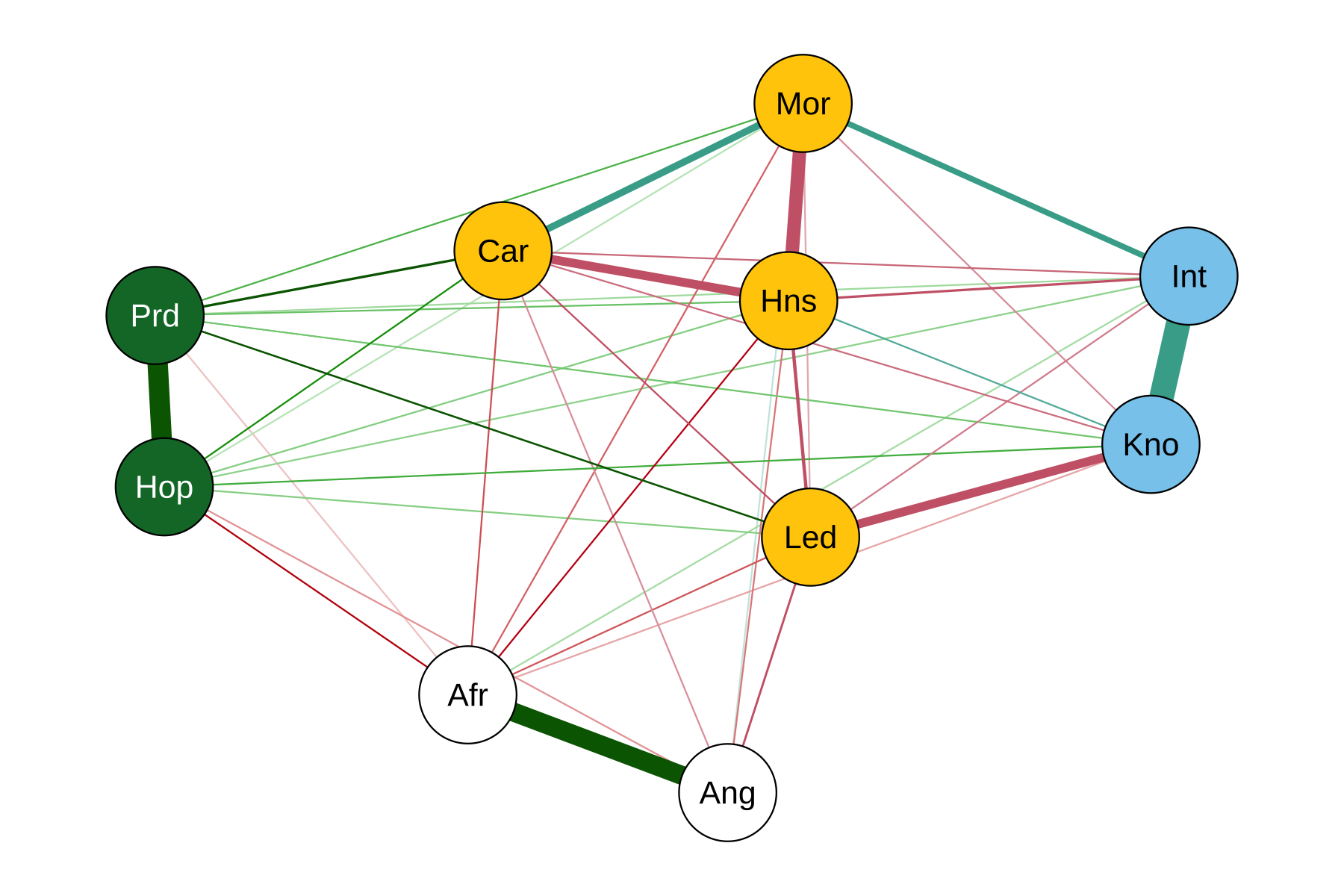
We can use Isingfit and add community detection:
Obama <- read.table("data/Obama.txt", header = TRUE) # see book data folder
ObamaFit <- IsingFit(Obama, plot = FALSE)
ObamaiGraph<- graph_from_adjacency_matrix(abs(ObamaFit$weiadj),
'undirected', weighted = TRUE, add.colnames = FALSE)
ObamaCom <- cluster_walktrap(ObamaiGraph)
qgraph(ObamaFit$weiadj, layout = 'spring',
cut = .8, groups = communities(ObamaCom), legend = FALSE)Figure 6.21 shows the network. The red nodes represent negative feelings toward Barack Obama; the green nodes represent positive feelings; the light blue nodes represent judgments primarily related to interpersonal warmth; and the purple nodes represent judgments related to Obama’s competence. This community structure is consistent with the postulate of the Ising attitude model that similar evaluative responses cluster (Dalege et al. 2016). Finnemann et al. (2021) present additional examples and applications of other packages.
6.5 Challenges
A large amount of work has been done since the early work on network psychology, the mutualism model, and the paper on the network perspective on comorbidity. In particular, network psychometrics has taken off in an unprecedented way. One could say that modern psychometrics is being reinvented from a network perspective. For every type of data and research question, a network approach seems to be available. For example, there are R packages for meta-analysis from a network perspective (Salanti et al. 2014). I also note that much has been done to understand the relationship between network psychometrics and more traditional techniques such as item response theory (Marsman et al. 2018), factor models (Waldorp and Marsman 2022), and structural equation modeling (Epskamp, Rhemtulla, and Borsboom 2017). Nevertheless, there are still many challenges for both psychological network modeling and network psychometrics.
6.5.1 Psychological network modeling
Despite all the work on this, I can only conclude that this theoretical line of research is still in its infancy. The strength of the application to intelligence is that it provides an alternative to the \(g\) factor model, which is also nothing more than a sketch of a theory. The extensions of the mutualism model (de Ron et al. 2023; Savi et al. 2019) add new steps, but remain rather limited models. One reason for this state of affairs is that it is really hard to pinpoint the elementary processes involved in intelligence, and indeed in any psychological system.
This is perhaps less of a problem in the factor account because the indicators are interchangeable in a reflective factor model. Once one has a sufficiently broad set of indicators, the common cause estimate will be robust. In a formative model, each indicator contributes a specific meaning to the index variable. However, this is not a reason to prefer the common cause model (van der Maas, Kan, and Borsboom 2014).
The other modeling examples suffer from the same problem. In the clinical psychology models, we define the nodes either as the symptoms specified in the Diagnostic and Statistical Manual of Mental Disorders (DSM) or as the questions asked in interviews or questionnaires, with the advantage that we then have data to fit the model. But, again, we have no real way of knowing the elementary processes in clinical disorders and their interactions (Fried and Cramer 2017).
If we miss important elementary nodes, this may seriously affect the validity of our models and psychometric network analyses.
A way out has been mentioned in the context of the Ising attitude model, using the mean-field approximation. If we are only interested in the global behavior of the attitude (hysteresis, divergence), we can ignore the specification of the nodes (another interchangeable argument). But if one wants to intervene on specific nodes or links of a clinically depressed person, this is not sufficient.
In mean-field analyses, the specification of all nodes is less important.
Another critical point is that these models increase our understanding of psychological phenomena, but seemingly not our ability to predict or intervene. For example, the Ising attitude model helps us understand the role of involvement (attention) in the dynamics of attitudes. If this factor is too high, persuasion will be extremely difficult due to hysteresis. Anyone who has ever tried to argue with a conspiracy theorist knows what I mean. But too little attention is also a problem. In the model, these are people who are sensitive to the external field, for example, you tell them to clean their room, but as soon as you leave, the attitude falls back into random fluctuations. The message gets through but does not stick. I find this insightful, but I must admit that it does not provide us with interventions. We don’t know how to control attention or engagement, although more work can and will be done on this.
For intelligence, the model suggests that the active establishment of near and far transfer might be effective. A disappointing lesson from developmental psychology is that transfer does not always occur automatically (e.g., Sala et al. 2019). However, strategies for improving transfer do exist (Barnett and Ceci 2002) and, according to the mutualism model, should have a general effect.
In Chapter 1, Section 1.3, I mentioned the case of the shallow lake studied in ecology, where catching the fish was a very effective intervention, while addressing the cause, pollution, was ineffective due to hysteresis. Ecologists now know why this is so and have developed models to explain this phenomenon. However, I did not mention that this intervention was suggested not by modeling work but by owners of ponds who observed that ponds without fish sometimes spontaneously tipped to the clear state. This is not an uncommon path in science, and it may well occur in clinical psychology. The touted extraordinary successes of electroshock therapy for severe depression or new drugs (MDMA) for post-traumatic stress disorder could be our “fish.” But these claims have also been criticized (e.g., Borsboom, Cramer, and Kalis 2019; Read and Moncrieff 2022).
Although much more progress can be made in network modeling of psychological systems, it is advisable to be realistic. Progress in mathematical modeling of ecosystems has also been slow. The formalization of psychological models is of interest for many reasons (Borsboom et al. 2021), but will only be effective if we also make progress in other areas, such as measurement (Chapter 8).
Ecosystems and human systems are devilishly complex.
6.5.2 Psychometric network analysis
This approach is also not without its problems, some of which are related to the problems of psychological network modeling. For example, the definition of nodes and the risk of missing nodes in the data is a serious threat. This problem is not unique to network analysis; simple regression analysis suffers from the same risks. Another common threat to many applications of psychometric network analysis is the reliance on self-report in interviews or questionnaires. Generalizability, which may depend more on the choice of sample and measurement method than on the statistical analysis itself, is another example of a common problem in psychology in general, and psychometric network analysis in particular.
Psychometric network analysis has been criticized because the results are difficult to replicate (Forbes et al. 2017). Replication of advanced statistical analyses, whether structural equation modeling, fMRI, or network psychometrics, is always an issue, but some solutions have been developed (Borsboom et al. 2017, 2018; Burger et al. 2022).
For network analysis, a number of safeguards have been developed to increase replicability
A final important issue concerns causality. Network models estimated from cross-sectional data are descriptive rather than causal; that is, they do not provide information about the direction of causal relationships between variables. Developing methods for inferring causality from network models is an important challenge in the field.
The move to time-series data (either \(N=1\), \(N>1\), or panel data) partially solves this problem (Molenaar 2004). With time-series data, we can establish Granger causality, a weaker form of causality based on the predictive power of one variable over another in a time-series analysis. However, the relationship may be spurious, influenced by other variables. Network analysis on time series often requires a lot of reliable and stationary data. An important issue is the sampling rate of the time series. In general, to accurately estimate a continuous time-varying signal, it is necessary to sample at twice the maximum frequency of the signal. This is called the Nyquist rate. Another issue is the assumption of equidistance between time points (Epskamp et al. 2018), which can be circumvented by using continuous-time models (Voelkle et al. 2012).
Granger causality suggests a directional influence when one time series predicts another, without necessarily implying a true causal relationship.
While these problems are not unique to network psychometrics, they are serious problems in practice (see Hamaker et al. 2015; Ryan, Bringmann, and Schuurman 2022). The ultimate test of causality requires intervention. For new work along this line, I refer to Dablander and van Bork (2021) and Kossakowski, Waldorp, and van der Maas (2021).
Hopefully, the combination of observational and experimental data can provide sufficient information to properly estimate causal relationships in directed acyclic graphs.
Perhaps we can also think of other ways. A simple, but difficult to implement, procedure is to ask subjects about the links in their networks. If one claims not to eat meat because of its effect on the climate, one might consider adding a directed link to this individual’s network (Rosencrans, Zoellner, and Feeny 2021). Deserno et al. (2020) used clinicians’ perceptions of causal relationships in autism. These relationships were consistent with those found in self-reported client data. The main problem is that there are many more possible links than nodes to report on, which makes the questionnaires extremely long and tedious to fill out. Brandt (2022) applied conceptual similarity judgments to construct attitude networks. Alternatively, one could try to estimate links from social media data, interviews, or essays using automatic techniques (Peters, Zörgő, and van der Maas 2022).
6.6 Conclusion
Despite these critical remarks, it is safe to say that the psychological network approach has made great progress in a very short time. The mutualism paper was only published in 2006. It is a new and unique application of the complex-systems approach within the field of psychology. For me, the common-cause approach is theoretically unsatisfactory because the common causes are purely hypothetical constructs. For both the \(g\) and \(p\) factors, there is no reasonable explanation for their origin. In contrast, the reciprocal interactions between function and symptoms that underlie the network theories of intelligence and psychopathology are hardly controversial. It is also good to note that the network approach is not inconsistent with statistical factor analytic work in psychology. It is a matter of interpreting the general factor as a common cause or as an index. The formative interpretation of factors is consistent with the network approach.
In the next chapter, we take the step to modeling social interactions using social networks, where the nodes represent agents that move to new locations, learn a language, share cultural attributes, and have opinions. The focus is on opinion networks. The chapter ends with our own agent-based model of opinion dynamics, which builds on the Ising attitude network model. This opinion model is a social network of within person attitude networks. To simplify we will use the cusp description of the Ising attitude network model at the within-person level. In essence, the model is based on interacting cusps, similar to the model for multifigure multistable perception introduced in Chapter 4 (Section 4.3.8). This opinion model suggests a new explanation and a new remedy for polarization.
6.7 Exercises
Reproduce the degree distribution of the Barabási—Albert model shown on the scale-free network Wikipedia page. Use sample_pa from the igraph library. (*)
Open and run the “Preferential Attachment” model in NetLogo. Replace the line
report [one-of both-ends] of one-of linkswithreport one-of turtles. New nodes will now connect to a random node. Does this result in a random network? (*)Make a hysteresis plot in the “Vulnerability to Depression” model in NetLogo (see Section 6.3.2). (*)
In the “Vulnerability to Depression” model you can deactivate all symptoms at once with the
administer-shockbutton. It is as if you give the network an electric shock that resets all the symptoms. Try to find a settings of theconnection-strengthandexternal-activationthat creates a disordered network (above the black line in thenetwork statusplot) whereby administering a shock makes the system healthy again. Is this healthy state long-term stable? (*)Compute the Gibbs entropy for the Learning Ising Attitude model during the learning process (see Section 6.3.3.4). Show in a plot that learning minimizes the Gibbs entropy. (**)
Install and open JASP (jasp-stats.org). Open the data library: “6. Factor.” Read all the output and add a confirmatory factor analysis. What is the standardized factor loading of Residual Pitch in the confirmatory one-factor model? (*)
Read the blog “How to Perform a Network Analysis in JASP”8 Reproduce the top plots of figure 6.18. Generate the data using the R code in Section 6.4.2, import the data into JASP, and perform the network analysis. (*)
Study the R code for the case where the M-matrix consists of three blocks (Section 6.4.2). Generate the data and import into JASP. Apply exploratory factor analysis, check the fit for 1 to 3 factors, and report the \(p\)-values. Fit the confirmatory 3-factor model. Does it fit? Add V1 to the second instead of the first factor. How do you see the misfit? (*)
How can you generate data for a higher-order factor model using the mutualism model? What should be changed in the code of the M-matrix for the case of three blocks? Show that the three-factor solution (assuming uncorrelated factors) does not fit the resulting data. Fit a higher-order factor model and report the \(p\)-value of the goodness of fit. How does the network plot change? (**)
Generate data for a network in a cycle (v1 -> v2 -> v3…v12 -> v1). Fit a network and an exploratory factor model. Does this work? What does this tell us about the relationship between the class of all network models and all factor models? (**)
Fit a Bayesian network in JASP to the data generated for figure 6.20. Warning: the GM in JASP expects (0,1) data. Check that only the simulated links have high Bayes factors. (*)
Amazingly, In fact, most people are only four or five handshakes away from Napoleon.↩︎
The original title of this paper was “No Reason to \(p\),” but the editor did not think it was funny.↩︎
Assuming that all the attitude states (items) are re-encoded as positive (or negative) valued items.↩︎
You may want to start by reading the blog post on doing network analysis in JASP (https://jasp-stats.org/2018/03/20/perform-network-analysis-jasp/).↩︎
https://jasp-stats.org/2018/03/20/perform-network-analysis-jasp/↩︎